V8 Pwn Basics 2: TurboFan
众所周知, JS 是解释语言, 解析完 AST 后生成字节码, 然后在 VM 上解释运行. 当一个函数运行了很多次之后, 就会尝试编译成二进制机器码, 从而加速执行. 本文将从字节码开始, 介绍 V8 是如何进行优化和编译的.
调用栈
VM 会根据字节码操作一些 “寄存器”, 除了累加寄存器外, 每个函数都有独立的 “寄存器”, 并且会分配在栈上, 其实可以直接理解为局部变量.
函数的栈帧如下:
左边是新的, 右边是旧的, 区别在于压入参数的顺序以及一个 Argc. 旧的栈帧在处理不匹配参数个数的函数调用上还额外有 适配器帧, 而新版则不需要这个.
最开始的部分和 x86 C 语言的调用规则类似, 先按顺序压入参数, 然后是返回地址以及上一个栈帧的指针.
接着压入 JSFunction, Context, Bytecode Array 和 Bytecode Offset. 函数是一个 Object, 在 V8 中是 C++ class JSFunction. 栈上的 JSFunction 就是当前函数 Object 的地址, 也称为 闭包. Context 是上下文对象指针, 具体作用暂时没搞懂, 跳过. Bytecode Array 指向一个 C++ 对象 class Bytecode, 它除了保存字节码序列以外, 还保存了一些信息, 比如字节码的入口, 函数用到的常量 (常量池) 等.
最后再压入所需要的寄存器, 并初始化为 Undefined.
Bytecode
启动 d8 时添加 --print-bytecode 标志, 可以打印字节码以及相关信息. (当时编译了一个 2018 年的 d8 准备边做题, 更新版本的输出信息更多)
比如写一个这样的代码:
|
|
生成的 incX 函数字节码如下:
[generated bytecode for function: incX]
Parameter count 2
Frame size 0
13 E> 0x969d2ea71da @ 0 : a1 StackCheck
31 S> 0x969d2ea71db @ 1 : 28 02 00 01 LdaNamedProperty a0, [0], [1]
33 E> 0x969d2ea71df @ 5 : 3e 01 00 AddSmi [1], [0]
37 S> 0x969d2ea71e2 @ 8 : a5 Return
Constant pool (size = 1)
0x969d2ea7171: [FixedArray] in OldSpace
- map: 0x34d9a96028b9 <Map>
- length: 1
0: 0x0969d2ea3469 <String[1]: x>
Handler Table (size = 0)
LdaNameProperty ai, off 是加载命名属性的值到累加寄存器中, ai 是函数的第 i 个参数 (除去 this), 之后的 [0] 表示第几个命名属性, 对于刚刚传入的 {x: 1337} 这个对象来说, 就是第 0 个. 最后一个 [1]
表示将类型推导信息放在 反馈向量的哪个位置.
AddSmi imm 是累加寄存器加一个 SMI, 这里是加 1. 最后的 [0] 表示将类型推导信息放在反馈向量的哪个位置.
所有字节码可以在 这里 查到. (或者直接翻源码)
在实现细节上, Ignition 对每一个字节码都有一个处理函数 Handler. 比如 LdaZero:
|
|
可以看到, 在处理完之后调用了 Dispatch() 函数. 这个函数用来调用下一个字节码的 handler.
Feedback Vector
机器码无法支持动态类型, Ignition 在生成和执行字节码的时候就会收集关于类型的反馈信息, 之后 TurboFan 基于假设的类型来生成机器码. (当然在执行机器码之前需要检查类型)
%DebugPrint(incX) 可以查看函数的反馈向量:
- feedback vector: 0x969d2ea71f9: [FeedbackVector] in OldSpace
- map: 0x34d9a9602cc9 <Map>
- length: 3
- shared function info: 0x0969d2ea3539 <SharedFunctionInfo incX>
- optimized code/marker: OptimizationMarker::kNone
- invocation count: 1
- profiler ticks: 0
- slot #0 BinaryOp BinaryOp:SignedSmall {
[0]: 1
}
- slot #1 LoadProperty PREMONOMORPHIC {
[1]: 0x34d9a9640529 <Symbol: (premonomorphic_symbol)>
[2]: [weak] 0x1870fd00c6b1 <Map(HOLEY_ELEMENTS)>
}
反馈向量存储一些操作, 比如 obj.x + 1 则会记录 obj.x 和数字 1 进行了一个加法运算. 通过这些信息, 能够推测 obj.x 的类型, 比如能和数字 1 做加法的可能是数字或者字符串.
TurboFan
opt and deopt
当一个函数 (参数类型不变) 执行了很多次之后, V8 认为它还会继续执行, 于是采用 Just In Time 的技术将该函数编译成机器码, 这样之后执行该函数的速度就大大提升. 但是现在这个已经编译过的函数只能处理一种类型的参数, 如果下次调用的参数类型改变了, 那么无法继续使用编译过的代码执行. 在调用机器代码之前, 必须检查参数类型, 如果类型不符合, 则会进行 去优化. 这个检查功能称为 类型保护
考虑如下代码:
|
|
使用 --trace-opt 和 --trace-deopt 以及 --allow-natives-syntax 运行 d8.
可以看到第一句 DisassembleFunction 打印出的 add 函数信息如下:
0x263fcbc0d021: [Code]
- map: 0x05e932282ae9 <Map>
kind = BUILTIN
name = InterpreterEntryTrampoline
compiler = unknown
address = 0x263fcbc0d021
Instructions (size = 995)
...
可以看到是没有优化过的, 反编译出来的指令有 995 个字节. 这些指令就是 Ignition 执行的代码, 包括建立栈帧, 调用字节码等等.
调用了多次 add() 之后, 进行了编译, 可以看到打印 TurboFan 编译信息:
[marking 0x3b521cfa3799 <JSFunction add (sfi = 0x3b521cfa3529)> for optimized recompilation, reason: small function, ICs with typeinfo: 1/1 (100%), generic ICs: 0/1 (0%)]
[compiling method 0x3b521cfa3799 <JSFunction add (sfi = 0x3b521cfa3529)> using TurboFan]
[optimizing 0x3b521cfa3799 <JSFunction add (sfi = 0x3b521cfa3529)> - took 5.232, 1.805, 0.066 ms]
[completed optimizing 0x3b521cfa3799 <JSFunction add (sfi = 0x3b521cfa3529)>]
[marking 0x3b521cfa36b9 <JSFunction (sfi = 0x3b521cfa3479)> for optimized recompilation, reason: hot and stable, ICs with typeinfo: 4/6 (66%), generic ICs: 0/6 (0%)]
[compiling method 0x3b521cfa36b9 <JSFunction (sfi = 0x3b521cfa3479)> using TurboFan OSR]
[optimizing 0x3b521cfa36b9 <JSFunction (sfi = 0x3b521cfa3479)> - took 2.190, 4.002, 0.114 ms]
前面几条是编译 add() 的信息 (<JSFunction add (sfi = 0x2ba30ca23529)>), 后面是编译循环 for (let i = 0; i < 0x10000; i++) add(i) 的, 可以看到用的是 TurboFan OSR (on-stack replacement). OSR 是在函数运行时 (栈帧不变, 所以叫 on-stack) 的即时编译.
接下来观察 DisassembleFunction 打印出来的信息如下:
0x263fcbccc601: [Code]
* map: 0x05e932282ae9 <Map>
kind = OPTIMIZED_FUNCTION
stack_slots = 5
compiler = turbofan
address = 0x263fcbccc601
类型从 BUILTIN 变为了 OPTIMIZED_FUNCTION, compiler 也变为了 turbofan, 指令大小也降低到了 208
在指令中, 能够看到检查类型的代码:
Instructions (size = 208)
...
0x263fcbccc6ae 6e 488b4510 REX.W movq rax,[rbp+0x10]
0x263fcbccc6b2 72 a801 test al,0x1
0x263fcbccc6b4 74 0f8545000000 jnz 0x263fcbccc6ff <+0xbf> /* check smi */
0x263fcbccc6ba 7a 488bd8 REX.W movq rbx,rax
0x263fcbccc6bd 7d 48c1eb20 REX.W shrq rbx, 32
0x263fcbccc6c1 81 83c301 addl rbx,0x1
0x263fcbccc6c4 84 0f803a000000 jo 0x263fcbccc704 <+0xc4>
0x263fcbccc6ca 8a 48c1e320 REX.W shlq rbx, 32
0x263fcbccc6ce 8e 488bc3 REX.W movq rax,rbx
0x263fcbccc6d1 91 488be5 REX.W movq rsp,rbp
0x263fcbccc6d4 94 5d pop rbp
0x263fcbccc6d5 95 c21000 ret 0x10
...
0x263fcbccc6ff bf e83c790300 call 0x263fcbd04040 ;; debug: deopt position, script offset '27'
;; debug: deopt position, inlining id '-1'
;; debug: deopt reason 'not a Smi'
;; debug: deopt index 0
;; eager deoptimization bailout 0
0x263fcbccc704 c4 e83c790300 call 0x263fcbd04045 ;; debug: deopt position, script offset '27'
;; debug: deopt position, inlining id '-1'
;; debug: deopt reason 'overflow'
;; debug: deopt index 1
;; eager deoptimization bailout 1
0x263fcbccc709 c9 e83c790b00 call 0x263fcbd8404a ;; debug: deopt position, script offset '12'
;; debug: deopt position, inlining id '-1'
;; debug: deopt reason '(unknown)'
;; debug: deopt index 2
;; lazy deoptimization bailout 2
0x263fcbccc70e ce 6690 nop
...
RelocInfo (size = 78)
0x263fcbccc6ff deopt script offset (27)
0x263fcbccc6ff deopt inlining id (-1)
0x263fcbccc6ff deopt reason (not a Smi)
0x263fcbccc6ff deopt index
0x263fcbccc700 runtime entry (eager deoptimization bailout 0)
0x263fcbccc704 deopt script offset (27)
0x263fcbccc704 deopt inlining id (-1)
0x263fcbccc704 deopt reason (overflow)
0x263fcbccc704 deopt index
0x263fcbccc705 runtime entry (eager deoptimization bailout 1)
0x263fcbccc709 deopt script offset (12)
0x263fcbccc709 deopt inlining id (-1)
0x263fcbccc709 deopt reason ((unknown))
0x263fcbccc709 deopt index
0x263fcbccc70a runtime entry (lazy deoptimization bailout 2)
...
可以看到, 除了检查类型以外, 还会有其他检查如溢出.
接下来执行了 add("string"), 参数变为了字符串. 这时刚刚编译的代码就无法使用了. 所以这里会发生去优化. 不过这个去优化是 lazy 的, 下一次如果再调用 add("string"), 才会真正将 add() 函数去优化. 可以看到接下来第一次 add("strings") 执行完后, add() 函数还是已优化, 而又一次执行了 add("string") 后, 才变成了未优化 (去优化).
0x263fcbccc601: [Code]
- map: 0x05e932282ae9 <Map>
kind = OPTIMIZED_FUNCTION
stack_slots = 5
compiler = turbofan
address = 0x263fcbccc601
Instructions (size = 208)
...
0x263fcbc0d021: [Code]
- map: 0x05e932282ae9 <Map>
kind = BUILTIN
name = InterpreterEntryTrampoline
compiler = unknown
address = 0x263fcbc0d021
Instructions (size = 995)
...
Sea of Nodes
TurboFan 实现了一种基于图的的 中间表示 (IR): Sea of Nodes, TurboFan 的主要工作都是在这个图上操作.
图的节点有如下类型:
- 控制节点 , 如 if, while, 表示程序流
- 值节点 , 如数字常量, 堆上的常量
- JS 级别的操作节点 , 如
JSCall,JSAdd等类似字节码的操作 - VM 级别的操作节点 , 如分配空间, 从堆栈上取数据, 边界检查等
- 机器码级别的指令节点 , 如数字加, 比较大小等, 最低级的代码 / 指令.
根据节点的类型, 边也有不同的类型:
- 控制流边
- 值边
- 作用边
(其实不是很能分清除, 不过图能看懂个大概就行)
V8 有一个叫 Turbolizer 的工具, 能够可视化查看 sea of nodes, 方便理解或调试优化和编译的过程. 可以使用在线版本 Turbolizer
使用 --trace-turbo 运行 d8, 会生成 .cfg 和 .json 文件, 在 Turbolizer 中打开就能够看到图了.
优化阶段
TurboFan 在 sea of nodes 上的操作是分阶段的, 每个阶段都会遍历图, 并且执行特定的操作. 下面会使用 Turboliezer 介绍重要的优化阶段.
以一个简单的函数举例:
|
|
加上 --trace-turbo 运行 d8, 目录下生成了 turbo-opt_me-0.json. 在 Turboliezer 中打开. 大概长这样 (我的浏览器有个 dark reader 拓展):
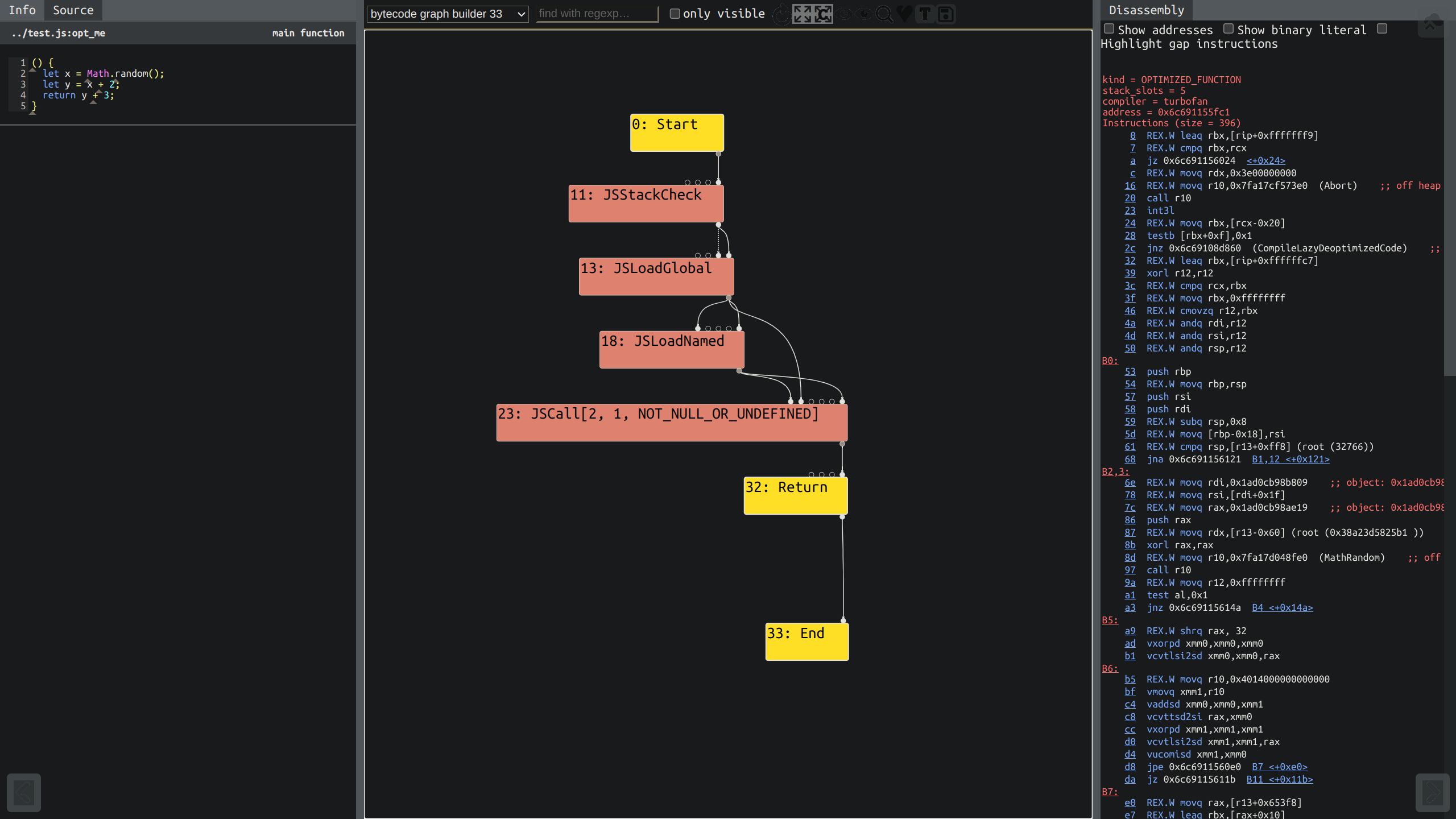
左边能够看到函数, 右边是汇编信息, 中间就是可视化的 sea of nodes 了. 中间上面下拉菜单可以选择阶段, 后面还有一些按钮选项, 挨个点过去就知道是什么了, 不介绍.
建图
第一步是根据字节码建图. 下拉菜单选择 bytecode grahp builder. 这里是将整个字节码建图了, 节点和边都比较多, 可以选择感兴趣的, 其他隐藏掉. 主要来关注一下代码逻辑的部分.

JSCall 对应的就是代码中调用的 Math.random(), 它和左边的常数 2 一起输入到 SpeculativeNumberAdd[Number] 节点中, 对应的是 y = x + 2. 类似地, 接下来对应的是 y + 3.
类型
下一个重要的阶段是确定节点的类型, 值节点代表着数据, 操作节点的返回值也是数据, 这些节点需要确定类型. 下拉菜单中选 typer, 并且选择 toggle types 按钮, 就可以看到节点的类型了. 依旧查看感兴趣的节点.

Math.random() 以及 SpeculativeNumberAdd[Number] 返回的数据类型是 PlainNumber, 而数字常量是 Range. Range 是一个闭区间类型, 表示这个区间里的数都有可能取到. 两个数都是常量, 所以左右都是一样的值.
降级和消除
接下来是要降低代码的等级, 以消除高级表示, 建立低级代码. 同时这个阶段也会消除一些节点, 比如永远不会到达的代码. 下拉菜单中选择 typed lowing.
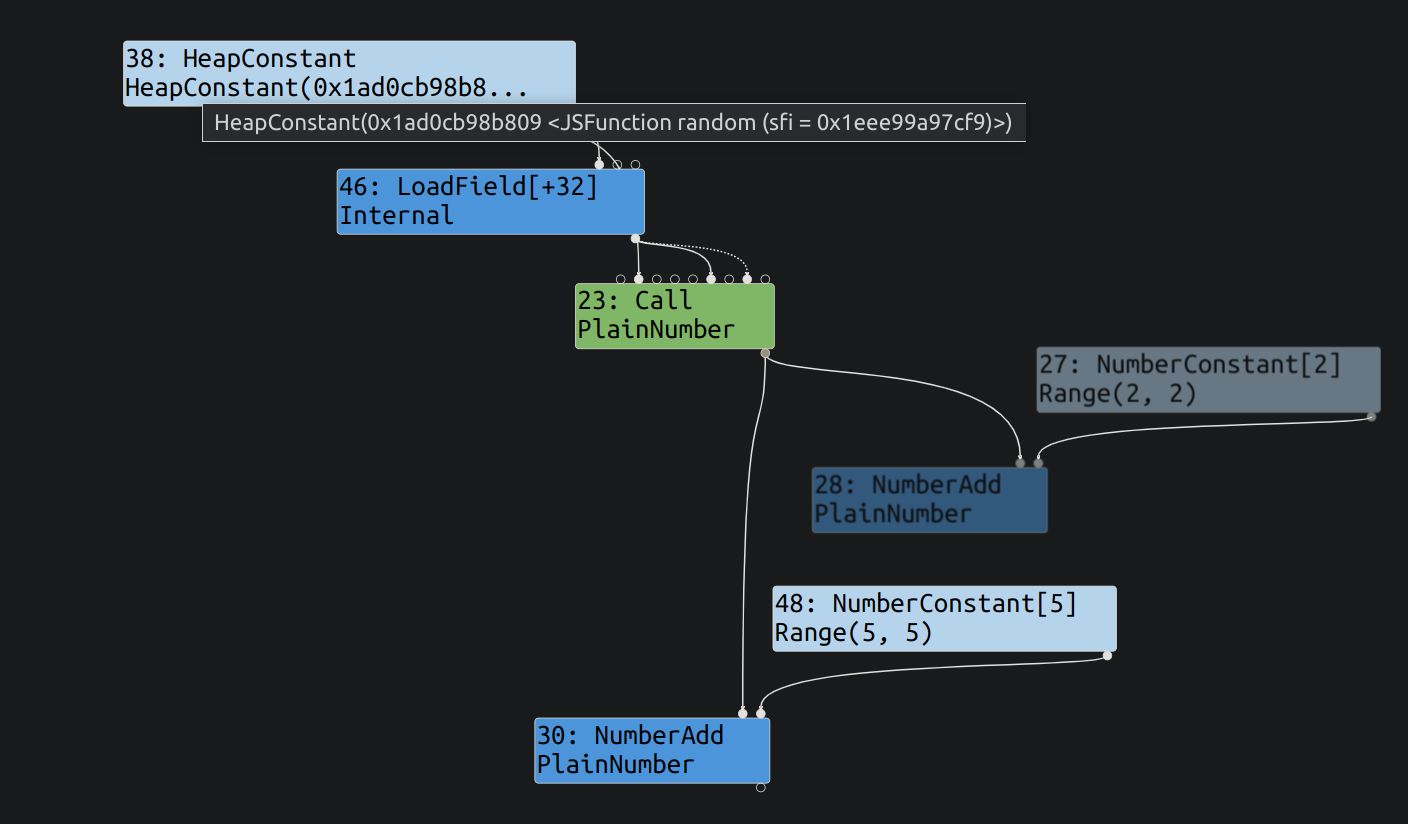
可以看到, JSCall 以及被降低成了类似 call(ptr) 这种形式, 同时加入了从堆上取函数地址的过程. 以及之后的 SpeculativeNumberAdd[Number] 变成了 NumberAdd.
边界检查
其实算一个小点, 但是越界是和利用息息相关的部分, 所以拎出来讲讲. 比如下面的代码:
|
|
选择 escape analysis 后 (不过好像在 typer 阶段就加入了这个 check bounds 了), 能够看到如下的图:
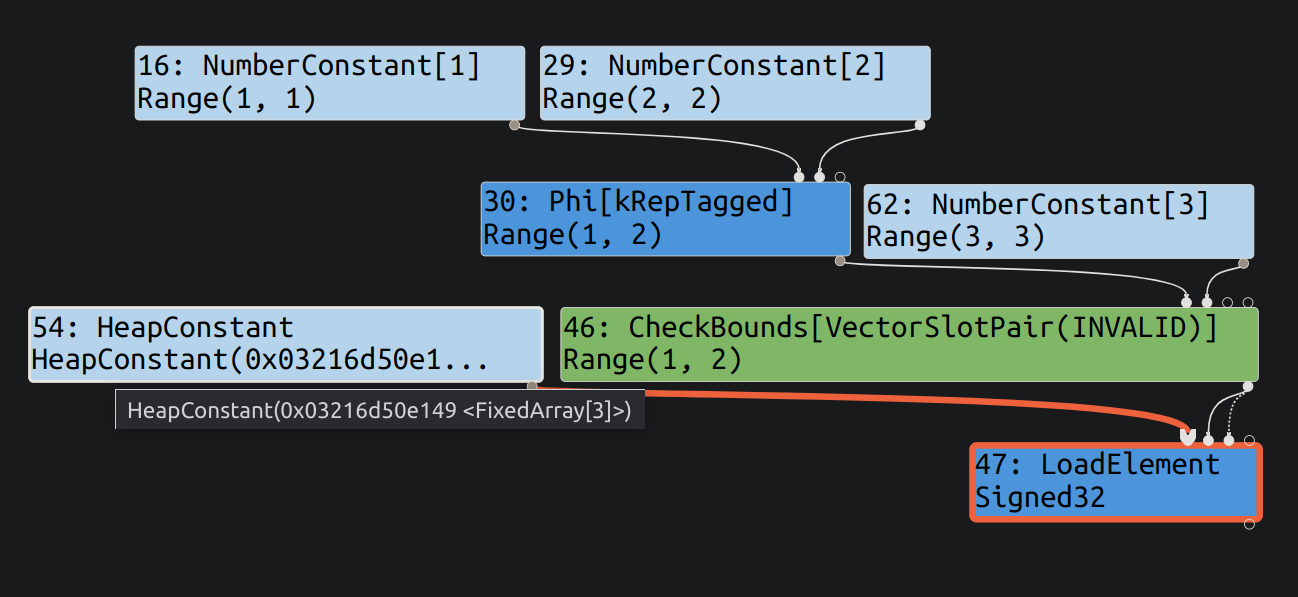
Phi 节点是从输入选一个. 代码中的变量 i 只可能是 1 或者 2, 所以这里检查边界后返回的是 Range(1, 2). 然后从数组中 load.
如果编译时设置了 v8_untrusted_code_mitigations = false 选项, 那么在下一个优化阶段 simplified lowering, 则会判断下标的 Range, 如果不超出数组长度, 则会将 check bounds 节点优化掉.
除了这些以外还有很多步骤, 全看了感觉也没必要, 暂时就了解一个大概就好了.
参考资料
- Chrome Browser Exploitation, Part 2: Introduction to Ignition, Sparkplug and JIT Compilation via TurboFan
- Introduction to TurboFan
- Ignition: V8 Interpreter
- Faster JavaScript calls
- JavaScript Bytecode – v8 Ignition Instructions
- V8 Bytecode Reference
- Sparkplug — a non-optimizing JavaScript compiler
- An internship on laziness: lazy unlinking of deoptimized functions
- 浅析 V8-turboFan(上)