2021 NCTF 南邮CTF校赛 部分 WP
被学弟带飞, 最后终榜 21 名, 校外 19 名 (也就是说这水平可以进南邮校队???)
本来想去写 pwn 的, 然后第一题不会. 有一个过了一万个人的 eaheap, 没学过堆, 也做不来. 周末还打 acm, 压根没时间学, 遂放弃.
然后开 RE 去了. 就写了俩, 其中一个是签到. RE 后面的题是 Windows 的 VC++, 看不懂在干嘛, 还是 GNU C++ 好看.
RE
WelcomeToNCTF-RE
签到, 丢进 IDA 后 flag 就写脸上了.
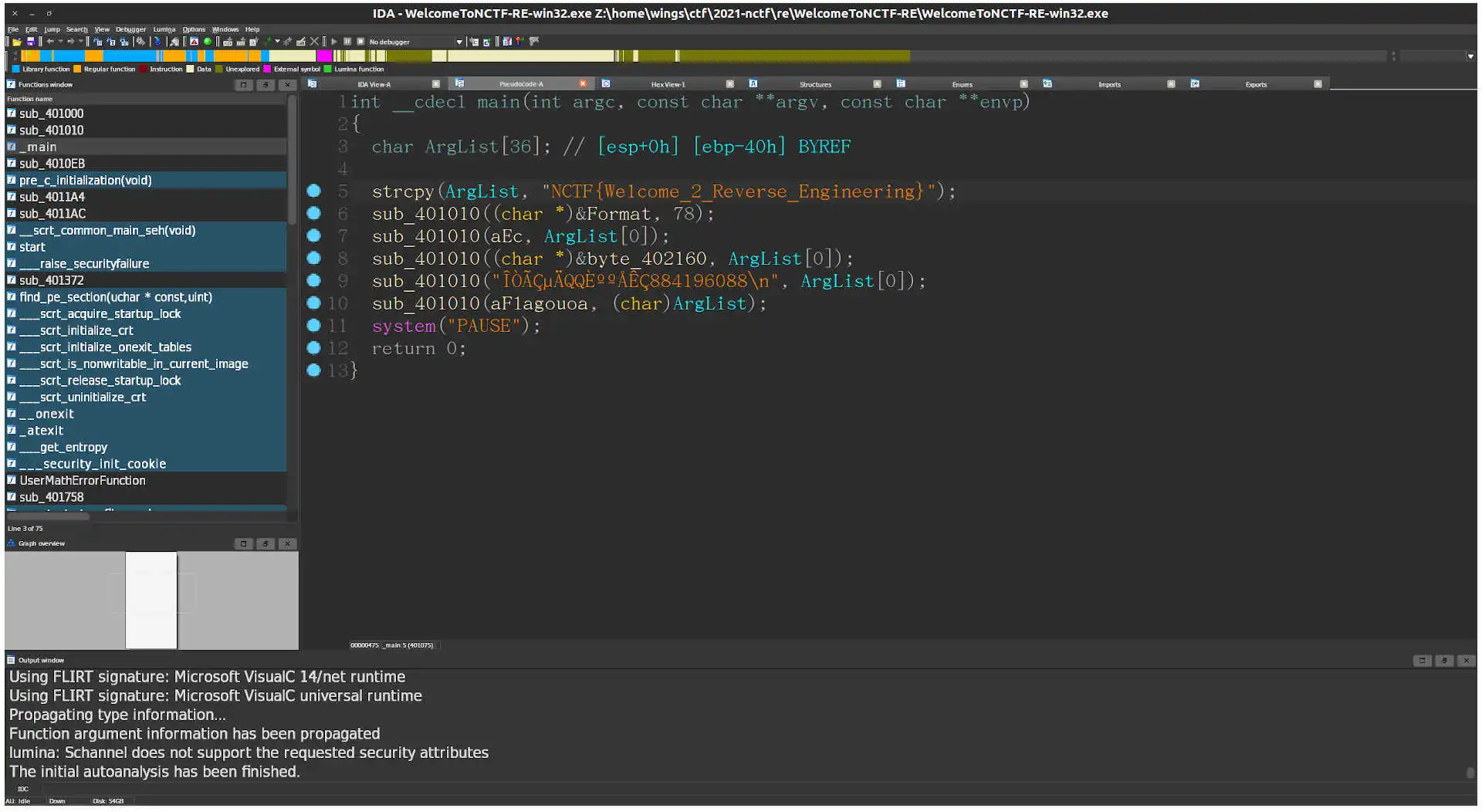
第五行字符串: NCTF{We1come_2_Reverse_Engineering}
Shadowbringer
丢进 IDA, GNU CPP 选手狂喜! 先看 main 函数,
youknowwhat()12 行调用函数 youknowwhat(), 先不管他, 继续往下看.
std::string::string(v4, "U>F2UsQXN`5sXMELT=:7M_2<X]^1ThaWF0=KM?9IUhAsTM5:T==_Ns&<Vhb!", &v6);
std::allocator<char>::~allocator(&v6);
std::operator<<<std::char_traits<char>>(refptr__ZSt4cout, "Welcome.Please input your flag:\n");
std::operator>><char>(refptr__ZSt3cin, (std::string *)Input);
std::string::string((std::string *)v8, (const std::string *)Input);15 行初始化 string 变量 v4 为后面那个诡异的字符串, 17 行输出提示信息, 18 行输入到 string 变量 v5. 接下来用 Input 代替 v5.
std::string::string((std::string *)v8, (const std::string *)Input);
Emet(v7, v8);
std::string::operator=(Input, v7);19 行把 Input 拷贝一份到字符串 v8, 20 行调用函数 Emet(v7, v8), 21 行把 Input 改成字符串 v7. 猜测 Emet() 函数是对字符串进行一个类似加密的过程.
std::string::string((std::string *)v10, (const std::string *)Input);
Selch(v9, v10);
std::string::operator=(Input, v9);24 - 26 行猜测是把加密过的字符串再进行一次 Selch() 加密.
if ( (unsigned __int8)std::operator==<char>(Input, v4) )
std::operator<<<std::char_traits<char>>(refptr__ZSt4cout, "Right.");
else
std::operator<<<std::char_traits<char>>(refptr__ZSt4cout, "Wrong.");29 - 32 行把两次加密后的输入与 v4 字符串比较, 相同就说明输入的是 flag.
大致浏览一下 Emet() 和 Selch(), 返回值是第一个传入的参数 a1, 证明这两个函数很可能就是对字符串加密的函数.
先来看 Emet() 函数.
函数有四个循环, 一个一个看.
第一个循环:
for ( i = 0; i < (unsigned __int64)std::string::size(a2); ++i )
{
v3 = (char *)std::string::operator[](a2, i);
std::bitset<8ull>::bitset(v14, (unsigned int)*v3);
std::bitset<8ull>::to_string(v13, v14);
std::operator+<char>(v12, &v9, v13);
std::string::operator=(&v9, v12);
std::string::~string((std::string *)v12);
std::string::~string((std::string *)v13);
}这部分代码逻辑很简单, 从前往后遍历输入字符串 a2 的每一个字符, 把它的 ASIIC 码值以 8 为二进制数的形式存在 bitset 里, 再转换成字符串, 拼接到字符串 v9 后面. 这里 bitset 仅起到一个工具的作用, 实际上这个循环做的事就是把每个字符替换成其 ASIIC 码对应的 8 位二进制数, 并连续存在字符串 v9 里.
第二个循环:
while ( 1 )
{
v4 = std::string::size((std::string *)&v9);
if ( v4 == 6 * (v4 / 6) )
break;
std::operator+<char>(v15, &v9, 48i64);
std::string::operator=(&v9, v15);
std::string::~string((std::string *)v15);
}如果刚刚替换后的 01 串 v9 的长度 v4(下面用 $len$ 指代) 满足条件 $len = 6 \cdot \left\lfloor\frac{len}{6}\right\rfloor$, 则退出, 否则在 01 串之后补 48(即字符 0), 直到满足条件. 这个条件其实就是 $6 | len$. 所以这段代码就是, 若刚刚替换后的 01 串长度不是 $6$ 的倍数, 则在其之后补 0 直到长度为 $6$ 的倍数.
第三个循环:
for ( j = 0; j < (unsigned __int64)std::string::size((std::string *)&v9); j += 6 )
{
std::string::substr((std::string *)v18, (unsigned __int64)&v9, j);
std::bitset<6ull>::bitset<char,std::char_traits<char>,std::allocator<char>>(v17, v18, 0i64);
v6 = std::bitset<6ull>::to_ulong(v17);
v7 = (char *)std::string::operator[](&hisoralce, v6);
std::operator+<char>(v16, a1, (unsigned int)*v7);
std::string::operator=(a1, v16);
std::string::~string((std::string *)v16);
std::string::~string((std::string *)v18);
}注意到 for 循环中 j += 6, 48 行取 01 串 v9 第 j 位开始的子串 v18, 然后 49 行用子串 v18 传入 6 位的 bitset 的构造函数中. 由 bitset 传入字符串构造函数的性质, 仅会取前 6 位存入 bitset<6> v17 中. 之后 50 行将取出的 6 位二进制数转换成十进制整数, 存入 v6. 51 行取字符串 hisoralce 的第 v6 个字符, 52, 53 行把这个字符接到 a1 某尾.
这里出现了一个奇怪的字符串 hisoralce, 双击它发现在 .bss 段:

可能是一个设定好的全局变量. 暂时不管它.
最后一个循环:
while ( (std::string::size(a1) & 3) != 0 )
{
std::operator+<char>(v19, a1, 33i64);
std::string::operator=(a1, v19);
std::string::~string((std::string *)v19);
}如果经过第三个循环转换后的字符串 a1 的长度 $len$ 不满足 $len\ \textrm{AND}\ 3 = 0$, 即不是 $4$ 的倍数, 则在 a1 之后接字符 !(33) 直到长度为 $4$ 的倍数.
这样, 整个函数就分析完了, 和之前想的一样, 是一个字符串加密函数.
然后去看一看另一函数, 发现和前一个函数几乎一模一样, diff 一下可以发现唯一的不同在于全局变量 hisoralce 换成了另一个全局变量 oralcehis.
接下来就是去寻找这两个全局变量.
最开始还有一个函数 youknowwhat(), 现在去看看它在干嘛.
for ( i = 0; i <= 63; ++i )
{
if ( i == 12 )
{
std::operator+<char>(v2, &hisoralce, 115i64);
std::string::operator=(&hisoralce, v2);
std::string::~string((std::string *)v2);
}
else if ( i == 57 )
{
std::operator+<char>(v3, &hisoralce, 104i64);
std::string::operator=(&hisoralce, v3);
std::string::~string((std::string *)v3);
}
else
{
std::operator+<char>(v4, &hisoralce, (unsigned int)(char)(i + 35));
std::string::operator=(&hisoralce, v4);
std::string::~string((std::string *)v4);
}
}很显然, 12 行开始的这个循环, 就是在构造 hisoralce 这个字符串.
枚举到 i==12 时, 把 s(115) 接到 hisoralce 末尾; 枚举到 i==57 时把 h(104) 接到 hisoralce 末尾; 其他情况把 (i+35) ASIIC 码对应的字符接到 hisoralce 末尾.
std::allocator<char>::allocator(&v5);
std::string::rend((std::string *)v6);
std::string::rbegin((std::string *)v7);
std::string::string<std::reverse_iterator<__gnu_cxx::__normal_iterator<char *,std::string>>>(v1, v7, v6, &v5);
std::allocator<char>::~allocator(&v5);
std::string::operator=(&oralcehis, v1);接下来这一堆我看不太懂, 但是看到了 rend, rbegin, reverse 这些函数, 猜测是在做一个翻转. 再看变量名 oralcehis 正好是 hisoralce 前后两个单词翻转, 进一步肯定了我的猜测.
到这里整个程序都看完了, 只有翻转一个地方是不太清楚的. 为了验证猜想, 先写了一个程序把 hisoralce 跑出来, 并翻转到和 oralcehis.
程序如下:
#include <iostream>
#include <algorithm>
#include <string>
using namespace std;
int main() {
string hisoralce;
for (int i = 0; i <= 63; ++i) {
if ( i == 12 )
hisoralce += (char)115;
else if ( i == 57 )
hisoralce += (char)104;
else
hisoralce += (char)(i+35);
}
cout << hisoralce << endl;
reverse(hisoralce.begin(), hisoralce.end());
cout << hisoralce << endl;
return 0;
}跑出来结果为:
hisoralce = "#$%&'()*+,-.s0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[h]^_`ab"
oralcehis = "ba`_^]h[ZYXWVUTSRQPONMLKJIHGFEDCBA@?>=<;:9876543210s.-,+*)('&%$#"
为了验证猜想, 把这两个加密函数写出来跑一跑:
#include <iostream>
#include <algorithm>
#include <string>
#include <bitset>
using namespace std;
string hisoralce = "#$%&\'()*+,-.s0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[h]^_`ab";
string oralcehis = "ba`_^]h[ZYXWVUTSRQPONMLKJIHGFEDCBA@?>=<;:9876543210s.-,+*)(\'&%$#";
string input;
string encode(string table, string org) {
string code = "", tmp = "";
for (auto c : org) {
bitset<8> b = (int)c;
tmp += b.to_string();
}
while (tmp.size() % 6)
tmp += '0';
for (int j = 0; j < tmp.size(); j += 6) {
bitset<6> b(tmp.substr(j));
code += table[b.to_ulong()];
}
while (code.size() & 3)
code += (char)33;
return code;
}
int main() {
cin >> input;
string code1 = encode(hisoralce, input);
string code2 = encode(oralcehis, code1);
cout << code1 << '\n' << code2 << '\n';
return 0;
}我们知道, flag 一定以 NCTF\{ 开头, 把这玩意输入进去看看, 结果为:
code1 = "6G074JO!"
code2 = "U>F2UsQXO0^!"
code2 前面几个正好是之前那个奇怪的 v4 (U>F2UsQXN`5s......) 的前面几个! 这证明了翻转的猜想是对的!
现在只需要反过来解码 v4 即可.
由于 hisoralce 和 oralcehis 中均无 ! 字符, 所以可以直接删掉密文之后的一些 !. 然后依次找每个字符在 hisoralce (或者 oralcehis) 中的出现位置, 以 6 位二进制 01 串的形式拼接. 之后把后面多余的 0 去掉, 再每 8 个一组作为二进制数, 并根据 ASIIC 码替换成相应字符, 最终得到原字符串.
分别用 oralcehis 和 hisoralce 解码即可. 程序如下:
#include <algorithm>
#include <iostream>
#include <bitset>
#include <string>
using namespace std;
string cd = "U>F2UsQXN`5sXMELT=:7M_2<X]^1ThaWF0=KM?9IUhAsTM5:T==_Ns&<Vhb!";
string hisoralce = "#$%&\'()*+,-.s0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[h]^_`ab";
string oralcehis = "ba`_^]h[ZYXWVUTSRQPONMLKJIHGFEDCBA@?>=<;:9876543210s.-,+*)(\'&%$#";
string decode(string table, string code) {
string org = "", t = "";
while (code.back() == '!')
code.pop_back();
for (auto c : code) {
int pos = table.find(c);
bitset<6> b = pos;
t += b.to_string();
}
while (t.size() % 8)
t.pop_back();
for (int i = 0; i < t.size(); i += 8) {
string sub = t.substr(i, 8);
bitset<8> b(sub);
org += (char)b.to_ulong();
}
return org;
}
int main() {
string d1 = decode(oralcehis, cd);
string d2 = decode(hisoralce, d1);
cout << d2 << '\n';
return 0;
}跑出来得到 flag 为: NCTF{H0m3_r1d1n9_h0m3_dy1n9_h0p3}