Intro to Kernel Pwn
要开始折磨自己了吗?
权限模型
文件权限
众所周知, 文件具有三种权限, user, group, world 的可读可写可执行, 同时还记录了所有者 (user) 和所有组 (group). ls -l 就能够查看文件对应的这些权限.
- 当使用文件所有者这个用户去访问文件, 会查看文件的 user 可读可写可执行权限;
- 当使用文件所有组中的用户去访问文件, 会查看文件的 group 对应权限;
- 当用户不是所有者也不在所有组内, 则会查看文件的 world 对应权限.
一个问题, 操作系统怎么知道访问这个文件的是谁.
以前我天真的认为, 我登录了这个用户, 我用任何程序访问文件都是具有这个用户对应的权限; sudo 是暂时切换到 root 用户执行后面的命令.
当然, 这是错的.
操作系统不是从某一个地方看当前登录的是哪个用户, 而是看访问文件的这个进程的 id.
进程凭证
每一个进程都有一些凭证, 由操作系统在 PCB 中维护.
linux 的 PCB 具体是 task_struct 这个结构体:
struct task_struct {
...
/* Process credentials: */
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred;
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
...
};其中的 cred 就是保存了这些 id 的结构体:
struct cred {
...
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
...
} __randomize_layout;- euid/egid: effective UID/GID, 有效 UID/GID, 用于访问其他对象时的权限检查
- suid/sgid: 切换 eUID/eGID 时保存原先值的地方, 用于暂时切换权限而已, 和一会介绍的 SUID 不同.
这里还有一个 real UID/GID, 以及 PCB 中还存在一个 real_cred. 这里的 real 表示的是这个进程的本身的凭证, 在进程被访问时, 具有的凭证.
一般来说, id = 0 表示 root, 具有最高的权限. id = 1000 开始是用户, 权限较低. 1000 以下是特殊用途的用户, 比如 www-data, nginx 等. fork 时子进程的 cred (包括 UID 等) 将继承父进程的.
举个例子, 进程 A 给进程 B 发送一个 kill signal (SIGKILL), 那么操作系统会检查 A 的 cred 中的 eUID, 检查 B 的 real_cred 中的 UID (real UID), 如果 A 的 eUID = 0, 那么 A 就可以 kill B; 反过来如果 B 的 UID = 0, A 的 eUID = 1000, 那么 A 就不能够 kill B.
操作文件的时候也是一样, 假设一个文件的权限是 rw-r--r--, 进程 A 的 eUID = 0 时可以写这个文件, 否则只能读这个文件, 不具有写的权限.
综上, cred 中的 eUID 才是操作系统检查当前进程主动操作的凭证.
SUID
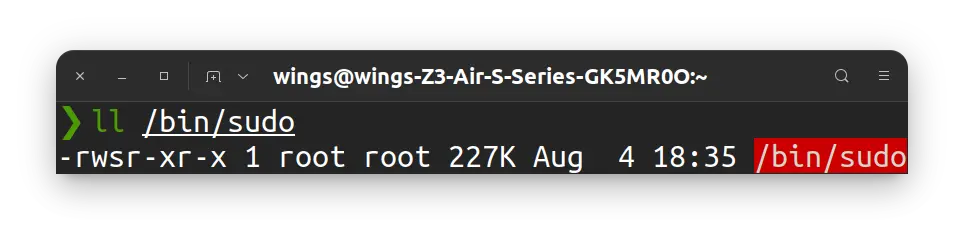
其实文件还有另外三个权限标志位, 其中一个是 SUID (Set UID) bit. 如果某个可执行文件的这一位为 1, 那么执行后进程的 eUID 将与 文件的所有者 一致. sudo 就是这个原理. 查看 /bin/sudo 可以看到, 这个文件的所有者是 root, 它的 SUID bit 是 1, 在 user 原来的 x 位置被标记了 s, 且文件被标红了.
Loadable Kernel Modules
Linux 采用宏内核, 如果要添加新的功能如外设驱动, 那么就必须重新编译整个内核.
LKMs 就是针对上述问题的解决方案. 操作系统支持向内核中安装可拓展的模块, 那么添加新的功能就不用重新编译了.
Kernel Module 是 ELF 文件, 一般以 .ko 作为后缀. 它无法独立运行, 只能运行在 kernel space 中. 也就是说, 它也是 kernel 的一部分.
insmod命令: 安装模块rmmod命令: 卸载模块lsmod命令: 查看已安装的模块
Kernel Module 会一般可以实现设备驱动, 文件系统, 网络功能等.
交互方式
Kernel Module 与用户交互主要有如下方式:
- 添加系统调用
- 修改中断响应
- 注册文件
其中, 添加系统调用的方法直接修改 kernel 的系统调用表, 存在极大的安全隐患, 已经不支持了. 添加中断响应往往意味着要使用中断命令 (如 int3), 高级语言不太适用. Unix 哲学一切皆文件, 和文件打交道就用 orw 那一套, 所以注册文件的方法较为通用.
文件一般注册在 /dev 或者 /proc 下, /dev 多用于设备, /proc 下是正在运行的程序的抽象, 被拓展还可以存放正在运行的 LKMs 的接口文件抽象.
接着就可以使用 open 打开这个接口文件, read / write 接收 / 发送数据. 除此之外, 还有一个系统调用 ioctl 提供了更通用的交互方式.
ioctl 的定义为 int ioctl(int fd, unsigned long request, ...), 第一个参数是文件描述符, 第二个参数是请求码, 之后跟的是参数. 这个系统调用最终会走向该 Module 的代码 (前提是写了), LKMs 判断请求码和额外数据, 更具请求码的不同实现 / 提供相应的功能.
Kernel Pwn in CTF
一般来说, CTF 赛事中的 Kernel Pwn 会加载自己写的一个 Kernel Module, 这个 Module 中存在漏洞, 我们需要在 user space 中通过与其交互的方式利用漏洞, 获得更高的权限去读取 flag.
改变自身 (e)UID
前面说过, 提升权限实际上是改变 UID. 除了最直接的在 kernel 内存中找到 task_struct 并改写外, 更简便的方法是使用 kernel 自己提供的功能.
commit_creds
程序在运行的过程中是支持改变权限 (或者说凭证) 的, kernel 中的 commit_creds(struct cred *) 函数就是用来干这个操作的. 它接收一个 cred 结构体, 然后将 task_struct 中的 cred 改为传入的.
prepare_kernel_cred
这个 cred 也不需要自己伪造, kernel 中的 prepare_kernel_cred 函数可以为我们创造一个. 完整定义为 struct cred * prepare_kernel_cred(struct task_struct *reference_task_struct)
有趣的是, 如果传入的参数是 NULL, 那么这个函数将会返回一个 root 的 cred!
那么我们只需要想方设法在 kernel space 中实现 commit_creds(prepare_kernel_cred(NULL)), 即可将进程的权限提升至 root.
或者, 内核有个 init 程序使用的 cred, 叫 init_cred, 它不是动态分配的, 而是一个静态变量, 如果我们可以知道它的地址, 也可以使用 commit_creds(init_cred) 提权.
返回用户态
内核态无法执行用户命令, 假如劫持了程序流, 我们还需要返回用户态. 如果将进程的 eUID 改变为 0, 可以访问只有 root 有权限的文件; 如果将 UID (RUID, Real UID) 改变为 0, 那么其子进程的 UID 也将是 0, 如果这个子进程是 shell, 那么我们将得具有最高权限的 root shell.
改变其他进程 (e)UID
还可以想办法在内存中找到其他进程 (通常是我们运行的恶意进程) 的 task_struct, 然后改变它的 UID, 这样另一个恶意进程也能够具有 root 权限, 而其本身就在用户态, 可以直接执行命令.
利用内核自身功能
内核的某些功能会执行特定的用户态程序, 并且具有 root 权限, 如果程序路径能够被劫持, 那么也可以得到一次 root 权限执行的机会.
比较通用的一个程序是 modprobe. 内核在安装或卸载模块时, 或者 execve 一个未知魔数的文件时, 会调用这个程序. 这个程序的路径是 /sbin/modprobe, 保存在内核全局变量 modprobe_path 中. 如果能够修改它到恶意程序, 并且触发内核执行 modprobe, 那么就能够以 root 权限执行恶意程序.
How to Pwn
笼统的方法和 user space 的 Pwn 一样, 都是控制执行流罢了. 在 user space, 我们与用户进程进行交互; 而在 kernel space, 我们与 LKMs 进行交互. LKMs 也可能会出现有各种各样可以利用的 bug, 如栈溢出, 堆溢出, UAF 等等.
有攻就有防, kernel 也有很多保护工作, 如 kernel 的 cannay, kernel 的地址随机化等等. 如何绕过这些保护, 也是 kernel pwn 需要学习的知识之一.
保护措施
- Kernel stack cookies: 相当于用户态下的 canary, 保护 kernel stack 不被溢出攻击的. 编译内核的时候就决定了是否开启.
- Kernel address space layout randomization (KASLR): 内核地址随机化, 相当于用户态下的 ASLR. qemu 的启动脚本在
-append中加入kaslr或者nokaslr来开启或关闭. - Supervisor mode execution protection (SMEP): 将用户空间的页面设置为不可执行, 实际上是由寄存器
cr4的第 20 位控制. qemu 的启动脚本在-cpu中加入+smep来启动, 在-append中加入nosmep来关闭. - Supervisor Mode Access Prevention (SMAP): 将用户空间的页面设置为完全无法访问, 实际上是由寄存器
cr4的第 21 位控制. qemu 的启动脚本在-cpu中加入+smap来启动, 在-append中加入nosmap来关闭. - Kernel page-table isolation (KPTI): 简单来说就是进程维护两张页表, 一张内核, 一张用户. 两张页表隔离. 用户页表除了 trap 所需的内核页面之外, 没有其他内核页面的映射; 而内核页表有对用户页面的所有映射. trap 时涉及到切换页表, 由
cr3寄存器控制. qemu 的启动脚本在-append中加入kpti=1或nopti来开启或关闭 KPTI. - Function Granular KASLR (FGKASLR): FGKASLR 会随机化大部分函数的偏移, 任何使用 C 语言编写的函数以及不在特殊输入节的函数都会单独作为一个节 (section), 之后会把这些节地址给随机化 (不过依旧保持相对位置不变), 这样我们泄漏了某些函数的地址, 并不能够得到其他函数的地址. 开启需要在编译时添加
CONFIG_FG_KASLR=y选项, qemu 的启动脚本在-append中加入nofgkaslr或者nokaslr关闭 kaslr.
由于一些版本可能默认开启保护, 启动脚本中可能没有写, 这时需要进入系统自行查看. smep, smap, kpti 可以可以用 cat /proc/cpuinfo | grep flags 查看, kaslr 可以用 dmesg | grep kaslr 查看.