MIT 6.S081 Fall 2020 Lab 1
Xv6 and Unix utilities
学! 狠狠地学!
环境搭建
https://pdos.csail.mit.edu/6.S081/2020/tools.html
总所周知, 我喜欢用新版的东西, 但是搞这玩意不得不用旧版… 所以把要用的干脆就放一起得了. 目录结构如下, 先看个大概:
❯ tree ~/MIT-6S081/ -L 1
MIT-6S081/
├── qemu-5.1.0
├── riscv64-toolchain
└── xv6-labs-2020
QEMU 5
为什么要用 5?
If you run make qemu and the script appears to hang after
qemu-system-riscv64 -machine virt -bios none -kernel kernel/kernel -m 128M -smp 3 -nographic -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
you’ll need to uninstall that package and install an older version
cd ~/MIT-6S081/
wget https://download.qemu.org/qemu-5.1.0.tar.xz
tar -xf qemu-5.1.0.tar.xz
cd qemu-5.1.0
./configure --disable-werror --target-list=riscv64-softmmu
make❯ ./riscv64-softmmu/qemu-system-riscv64 --version
QEMU emulator version 5.1.0
Copyright (c) 2003-2020 Fabrice Bellard and the QEMU Project developers
riscv64 gnu toolchain
源代码实在是太大了, 不如找个编译好的下载.
sifive 官方的 repo 中有 2020 年编译的, gcc 版本 8.
stnolting 的 repo 中有 9 天前 (你可以查看这篇文章的发布日期) 编译的, gcc 版本 12.
这里我们就用 sifive 的.
cd ~/MIT-6S081/
wget https://static.dev.sifive.com/dev-tools/freedom-tools/v2020.12/riscv64-unknown-elf-toolchain-10.2.0-2020.12.8-x86_64-linux-ubuntu14.tar.gz
tar -zxf riscv64-unknown-elf-toolchain-10.2.0-2020.12.8-x86_64-linux-ubuntu14.tar.gz -C ./riscv64-toolchain❯ ./riscv64-toolchain/bin/riscv64-unknown-elf-gcc --version
riscv64-unknown-elf-gcc (SiFive GCC-Metal 10.2.0-2020.12.8) 10.2.0
Copyright (C) 2020 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
乐, sifive 的 gdb 不支持 tui 模式, stnolting 需要 python3.8 运行库 (我是 3.10 的), 于是为了 tui 我还是自己编译了一遍.
需要注意的是, submodule 用了 gnu 官网的仓库, 比 github 还慢. make 后可以看信息, 然后自己去 github 上找镜像仓库 clone 过来. 最后这个仓库的文件夹有 13G… 16核编译了 14min… 编译出来有 1.8G.
Boot xv6
cd ~/MIT-6S081/
git clone git://g.csail.mit.edu/xv6-labs-2020
cd xv6-labs-2020
git checkout util然后需要修改一下 Makefile, 让它使用刚刚装好的 QEMU 和 riscv toolchain.
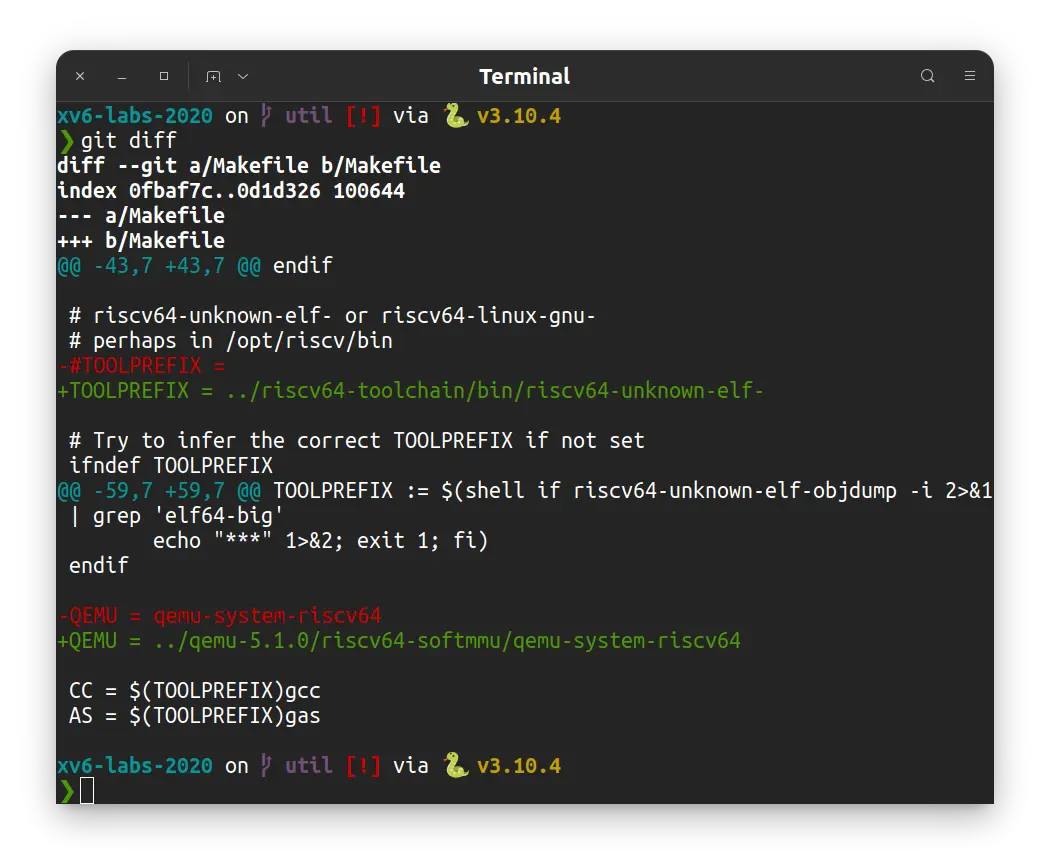
将 64 行的 #TOOLPREFIX = 设置 riscv toolchain 的位置, 并带上前缀:
TOOLPREFIX = ../riscv64-toolchain/bin/riscv64-unknown-elf-
将 64 行的 QEMU = qemu-system-riscv64 设置 qemu 的位置:
QEMU = ../qemu-5.1.0/riscv64-softmmu/qemu-system-riscv64
最后看起来应该是这样:
如果使用的是 gcc-12, 需要取消 Werror. Makefile 里搜这个编译选项, 然后删除即可.
make qemu 即可运行. 如果修改了文件, 要先 make clean.
❯ make qemu
...
../qemu-5.1.0/riscv64-softmmu/qemu-system-riscv64 -machine virt -bios none -kernel kernel/kernel -m 128M -smp 3 -nographic -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
xv6 kernel is booting
hart 1 starting
hart 2 starting
init: starting sh
$
Ctrl + a x 退出 QEMU.
sleep
查看 xv6 的系统调用, 有一条 sleep:
int sleep(int n) Pause for n clock ticks.
所以我们直接写一个程序, 去调用这个系统调用即可. 注意上述要求. 代码如下:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(2, "Usage: sleep NUMBER\n");
exit(1);
}
uint len = strlen(argv[1]);
for (int i = 0; i < len; i++)
if (!('0' <= argv[1][i] && argv[1][i] <= '9')) {
fprintf(2, "Invalid time interval '%s'", argv[1][i]);
exit(1);
}
uint n = atoi(argv[1]);
sleep(n);
exit(0);
}由于 atoi 没有对非数字返回错误, 这里我们这里处理一下 (虽然并不需要). 然后编辑 Makefile, 在 UPROGS 里加一行 $U/_sleep\.
make clean; make qemu 编译运行.
$ ls | grep sleep
sleep 2 20 23752
运行后, 可以看到 sleep 程序已经存在了. 运行试一下, 没有问题.
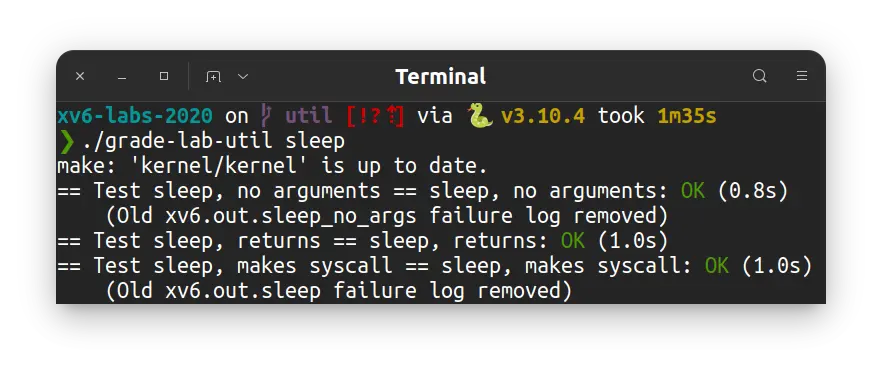
退出 QEMU, 运行 ./grade-lab-util sleep 评分:
后面简单的会的就直接放代码了.
pingpong
子进程 + 管道. 查看 xv6 的系统调用, 管道是匿名的, 直接用就行.
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#define READ 0
#define WRITE 1
int p[2];
int main() {
pipe(p);
int pid = fork();
if (pid > 0) {
int status;
write(p[WRITE], "ping", 4);
wait(&status);
char buf[10];
read(p[READ], buf, 4);
printf("%d: received %s\n", getpid(), buf);
exit(0);
}
else if (pid == 0) {
char buf[10];
read(p[READ], buf, 4);
printf("%d: received %s\n", getpid(), buf);
write(p[WRITE], "pong", 4);
exit(0);
}
else {
fprintf(2, "fork error");
exit(1);
}
}primes
先简单说明一下 CSP 并发模型.
我们熟知的并发模型是共享内存, 通过共享的信号量和锁来进行临界资源的原子操作. 而 通信顺序过程 模型是通过一个 没有缓存区的命名管道 进行的. 由于其没有缓存区, 且发送永远先于接收, 接收必须等发送完成才能进行. 于是整个多并发体系可以同步.
有趣的是, 模型里的发送方和接收方并不知道对方, 所以消息传递可以不是线性的. (虽然这里用不到, 只是觉得很好玩)
头大… 想了好久, 想到递归就找到路了.
第一个进程创建一个管道, 父进程输入数字, 子进程接收并进行筛法. 子进程采用递归的做法. 递归的参数是 left neighbor.
从其中读取第一个数, 筛法保证一定是素数. 建立一个新的管道 right neighbor 用来和它的子进程通信并同步. 父进程 (当前进程) 从 left neighbor 继续取, 如果不能被筛掉, 则写入 right neighbor 管道. 子进程 (当前进程的子进程) 调用筛法, 参数是 right neighbor 管道, 递归函数内进行下一个筛法处理.
说不明白… 写完就有 流水线 的感觉了. 从前面接收一个, 处理这一个, 将结果交由后面处理.
写代码的时候需要注意, 由于文件描述符有限, 所以不用的管道要 close 掉. 比如父进程只会向管道里写东西, 而不会从管道里读东西, 所以可以把读取端给 close 掉. 这个操作不会影响子进程, 因为每个进程虽然共享文件描述符, 但是都维护自己的文件打开列表, 并不共享.
若管道的输入端不被任何一个进程打开, 则 read 不会阻塞, 而是返回 EOF. (当然 xv6 里没有 EOF 这个宏, 这里可以认为 EOF = 0)
fork 只会在当前处产生分支, 父子进程走不同的路.
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#define READ 0
#define WRITE 1
#define EOF 0
void sieve(int pleft[]) {
close(pleft[WRITE]);
int prime;
if (read(pleft[READ], &prime, sizeof(prime)) == EOF)
exit(0);
printf("prime %d\n", prime);
int num;
int pright[2];
pipe(pright);
int pid = fork();
if (pid > 0) {
close(pright[READ]);
while (read(pleft[READ], &num, sizeof(num)) != EOF) {
if (num % prime != 0)
write(pright[WRITE], &num, sizeof(num));
}
close(pleft[READ]);
close(pright[WRITE]);
int status;
wait(&status);
exit(0);
}
else if (pid == 0) {
sieve(pright);
exit(0);
}
else {
fprintf(2, "fork error");
exit(1);
}
}
int main() {
int p[2];
pipe(p);
int pid = fork();
if (pid > 0) {
close(p[READ]);
for (int i = 2; i <= 35; i++)
write(p[WRITE], &i, sizeof(i));
close(p[WRITE]);
int status;
wait(&status);
exit(0);
}
else if (pid == 0) {
sieve(p);
exit(0);
}
else {
fprintf(2, "fork error\n");
exit(1);
}
}find
大模拟! 很容易想到递归. 参考 ls.c, 递归的参数是 file path, 这样就需要在 main 调用递归函数之前判断第一个参数是不是目录. fstat 查看文件状态, 可以看到是目录还是文件. 目录可以 open, 里面存的是 struct dirent[], 表示这个目录下面的每个文件. 这里面才有文件名. 处理一下这些文件的 path, 递归调用即可. 注意 . 和 .. 不要进去就行.
#include "kernel/types.h"
#include "kernel/stat.h"
#include "kernel/fs.h"
#include "kernel/fcntl.h"
#include "user/user.h"
void find(const char *path, const char *name) {
int fd = open(path, O_RDONLY);
if (fd < 0) {
fprintf(2, "find: cannot open %s\n", path);
exit(1);
}
struct stat st;
if (fstat(fd, &st) < 0) {
fprintf(2, "find: cannot fstat %s\n", path);
close(fd);
exit(1);
}
if (st.type == T_FILE) {
int i;
for (i = strlen(path); path[i-1] != '/'; i--);
if (strcmp(path + i, name) == 0)
printf("%s\n", path);
}
else if (st.type == T_DIR) {
char buf[256];
strcpy(buf, path);
char *p = buf + strlen(buf);
*p++ = '/';
struct dirent de;
while (read(fd, &de, sizeof(de)) == sizeof(de)) {
if(de.inum == 0)
continue;
if (strcmp(de.name, ".") == 0 || strcmp(de.name, "..") == 0)
continue;
if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf) {
printf("find: path too long\n");
close(fd);
exit(1);
}
memmove(p, de.name, DIRSIZ);
find(buf, name);
}
}
close(fd);
}
int main(int argc, char const *argv[]) {
if (argc != 3) {
fprintf(2, "Usage: find DIR FILENAME\n");
exit(1);
}
char dir[256];
if (strlen(argv[1]) > 255) {
printf("find: path too long\n");
exit(1);
}
strcpy(dir, argv[1]);
char *p = dir + strlen(dir) - 1;
while (*p == '/')
*p-- = 0;
int fd = open(dir, O_RDONLY);
if (fd < 0) {
fprintf(2, "find: cannot open %s\n", dir);
exit(1);
}
struct stat st;
if (fstat(fd, &st) < 0) {
fprintf(2, "find: cannot fstat %s\n", dir);
close(fd);
exit(1);
}
if (st.type != T_DIR) {
fprintf(2, "'%s' is not a directory\n", argv[1]);
close(fd);
exit(1);
}
find(dir, argv[2]);
exit(0);
}写得有点丑.
xargs
真不会 C 处理字符串, 解析参数写了好久…
这题主要是运用 fork exec 那套逻辑, 结果我卡在字符串处理了. 代码能力还是差了.
#include "kernel/types.h"
#include "kernel/stat.h"
#include "kernel/param.h"
#include "user/user.h"
int getline(char *buf) {
int cnt = 0;
while (read(0, buf, 1)) {
if (++cnt >= 256) {
fprintf(2, "xargs: line too long\n");
exit(1);
}
if (*buf++ == '\n')
break;
}
*(buf-1) = 0;
return cnt;
}
int prase(char *buf, char **nargv, const int max) {
int cnt = 0;
while (*buf) {
char *last = buf - 1;
if (*last == 0 && *buf != ' ') {
if (cnt >= max) {
fprintf(2, "xargs: args too many\n");
exit(1);
}
nargv[cnt++] = buf;
}
else if (*buf == ' ')
*buf = 0;
buf++;
}
nargv[cnt] = 0;
return cnt;
}
int main(int argc, char const *argv[]) {
if (argc == 1) {
fprintf(2, "Usage: xargs COMMAND ...\n");
exit(1);
}
char buf[257] = {0};
while (getline(buf + 1)) {
char *nargv[MAXARG + 1];
memcpy(nargv, argv + 1, sizeof(char *) * (argc - 1));
prase(buf + 1, nargv + argc - 1, MAXARG - argc + 1);
int pid = fork();
if (pid > 0) {
int status;
wait(&status);
}
else if (pid == 0) {
char cmd[128];
strcpy(cmd, argv[1]);
exec(cmd, nargv);
}
else {
fprintf(2, "fork error\n");
exit(1);
}
}
exit(0);
}Optional challenge exercises
附加题还是在写应用程序的感觉, 就不写了.
time
不是官方上面的 uptime.
本来写了个 time, 想着验证一下 CSP 并发筛法的时间. 结果由于文件描述符太少了, 数据跑不到大, 普通筛法和并发筛法小数据都是 1 tricks 跑完. 放一下 time 吧. 非常简单的 fork exec. 父进程调用 uptime 系统调用获取当前 tricks, 然后 wait 子进程 exec 完, 再调用一次 uptime 算时间差即可.
#include "kernel/types.h"
#include "kernel/stat.h"
#include "kernel/param.h"
#include "user/user.h"
int main(int argc, char const *argv[]) {
if (argc == 1) {
fprintf(2, "Usage: time COMMAND ...\n");
exit(1);
}
int pid = fork();
if (pid > 0) {
int start = uptime();
int status;
wait(&status);
int end = uptime();
printf("==============\ntime ticks: %d\n", end - start);
}
else if (pid == 0) {
char cmd[128];
strcpy(cmd, argv[1]);
char *nargv[MAXARG + 1];
memcpy(nargv, argv + 1, sizeof(char *) * (argc - 1));
exec(cmd, nargv);
}
exit(0);
}UPD: 发现 main 的 argv 参数类型不用 const 限制会方便很多…