「笔记」软件工程
第一章
软件
软件是程序, 数据及相关文档的完整集合
文档 + 程序
- ⽂档是软件质的部分
- 程序是⽂档代码化的表现形式
- 运行时提供程序
- 程序能够处理数据
- 程序能够按照预定的商业逻辑运行
- 描述程序功能需求以及程序如何操作的文档
软件危机
软件开发和维护中遇到的问题
- 怎样满足对软件日益增长的需求 (如何开发软件)
- 如何维护数量不断膨胀的已有软件 (如何维护)
说 nm 呢
产生原因:
两个方面, 1) 软件本身的特点 2) 软件开发维护的方法
- 客观: 软件本身
- 逻辑部件
- 规模庞大
- 主观: 不正确的方法:
- 忽视需求分析
- 忽视文档
- 轻视维护
解决方法:
- 组织管理
- 工程项目管理方法
- 技术措施
- 软件开发技术与方法
- 软件工具
软件工程
软件工程是知道计算机软件开发和维护的一门工程学科. 采用工程的概念, 原理, 技术和方法来开发维护软件.
软件生命周期
- 问题定义: 问题性质报告, 工程目标和规模报告, 对用户访问调查, 得到双方满意的文档
- 可行性研究: 导出系统的逻辑模型, 数据流程图, 在此基础上更准确, 更具体确定工程规模和目标, 更准确估计系统成本和效益.
- 需求分析: 和用户配合, 交流, 得出经过用户确认的系统逻辑模型, 通常用数据流程图, 数据字典和简要的算法表示
- 总体设计: 如何解决问题, 低成本完成最少的工作, 中成本完成一些附加功能, 高成本完成用户还可能希望有的功能
- 详细设计: 把任务具体化, 设计出详细的程序说明, 通常是 HIPO 图 或 PDL 语言
- 编码和单元测试: 写程序, 并测试每个模块
- 综合测试: 通过各种测试使软件达到要求
- 集成测试: 更具软件结构, 把模块按策略装配, 测试 (联调的意思)
- 验收测试: 按规格说明书的规定, 对目标系统进行验收
- 软件维护: 改正性, 适应性, 完善性, 预防性维护
软件生存周期模型
瀑布模型:
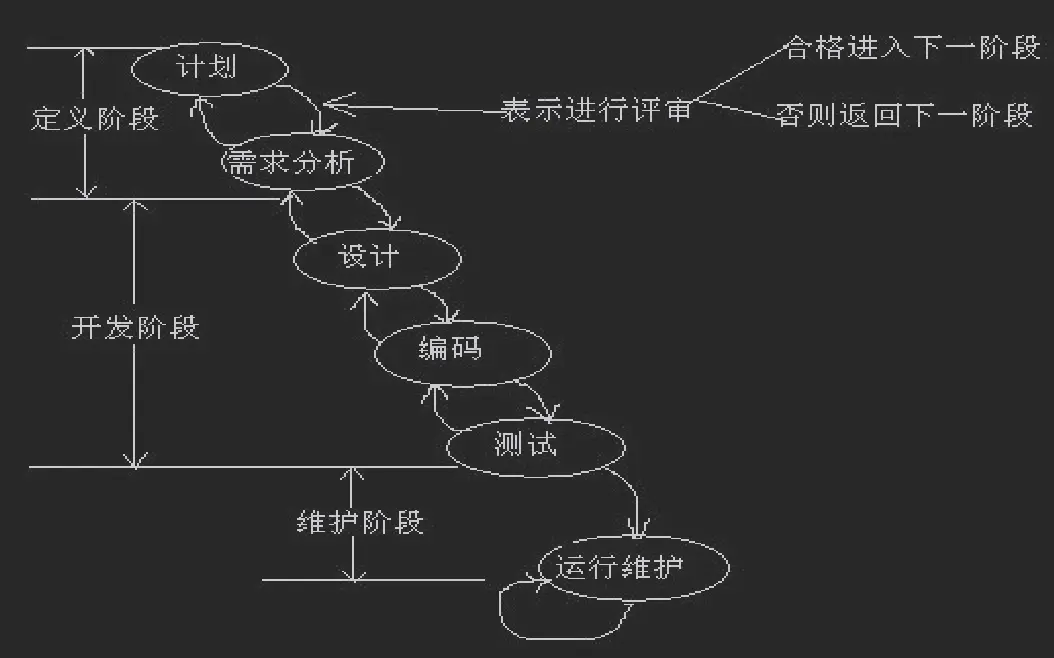
- 特征: 输入来自上一个活动的输出, 完成该项活动的内容, 活动的输出传给下一个活动, 对活动的实施工作进行评审.
- 适合: 需求明确的任务
- 优点: 使用阶段评审和文档控制, 有效对整个开发过程进行指导, 保证及时交付, 达到预期质量要求
- 缺点: 成品时间长, 缺乏灵活性
快速原型模型:
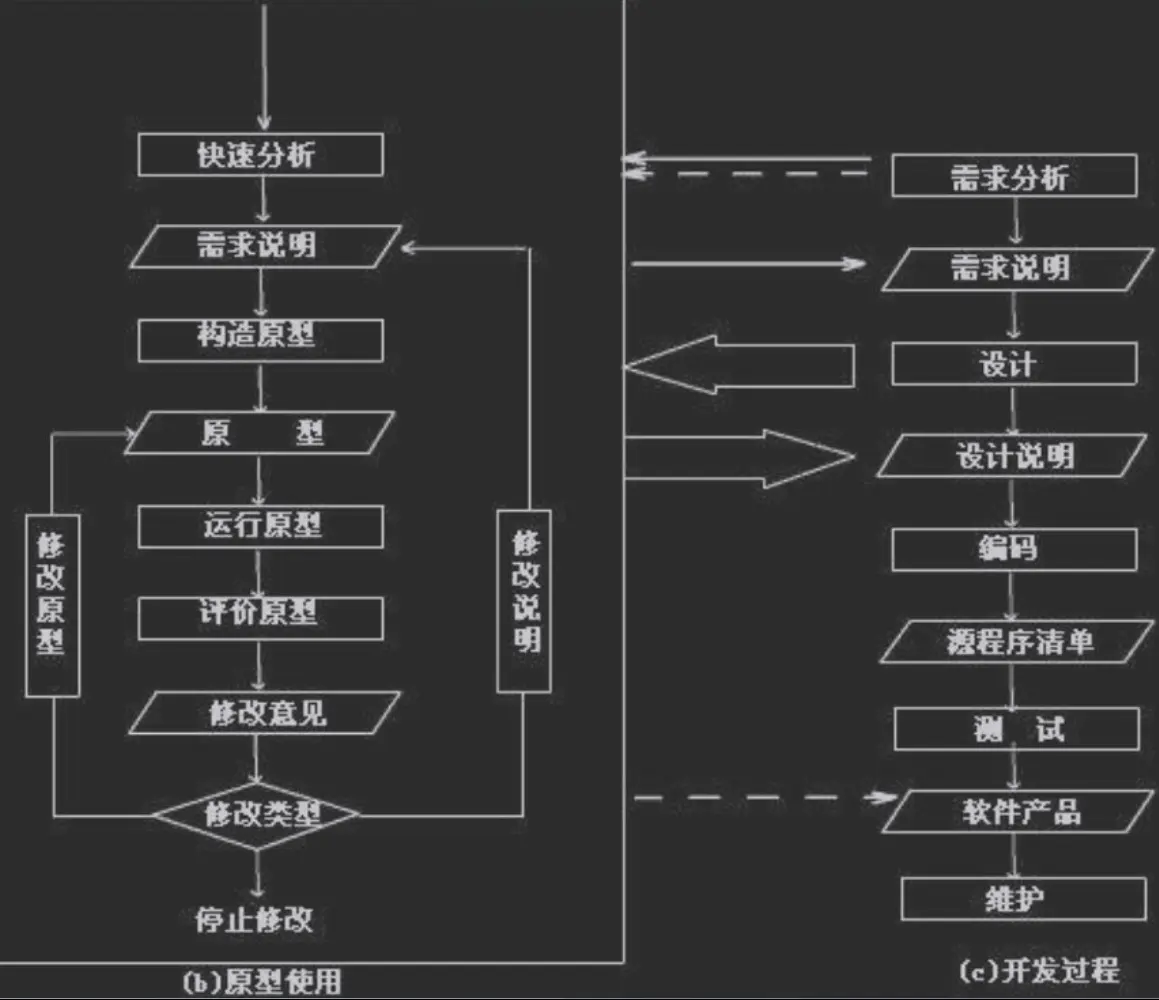
快速构建一个原型, 供用户使用反馈, 从而修改原型使得用户满意. UI 通常是快速原型的一个关键部分
- 特点: 允许用户在系统开发过程中完善需求
- 适合: 需求不那么明确, 需求会更变
- 优点: 系统开发时间短, 成本低, 用户和开发人员有效配合
- 缺点: 频繁的需求变化使开发进程难以管理. 技术上要求处理好原型集成的问题, 系统支撑结构和共享数据结构的规范问题
螺旋模型:

- 特点: 使用原型以及其他方法来降低风险. 可以看成是在每个阶段之前都加入了风险分析过程的快速原型模型
- 适合: 内部开发的大规模软件项目
- 优点: 对可选方案和约束条件的强调有利于已有软件的重用, 也有利于把软件质量作为一个重要目标. 减少了过多测试或测试不足带来的风险 (说你 🐴 呢)
喷泉模型, 智能模型
第二章
可行性研究: 用最小的代价在尽可能短的时间内确定问题是否能够解决
- 技术可行性
- 经济可行性: 经济效益 > 开发成本
- 操作可行性: 操作方式在用户组织内是否行得通 (啥玩意, 用户会不会用?)
- (法律可行性)
数据流图 DFD
- 方形: 数据源点或者终点
- 圆形: 数据处理 (加工)
- 箭头: 数据流
- 两条平行横线: 数据存储
需要有意义的命名
分层, 由外向里, 逐步完善
数据字典
数据字典是关于数据信息的集合, 即对数据流图中的元素进行定义
x = a + [b, c] + 2{d}5 + (e) + “f” + 1..9
和正则类似
- =: 定义
- +: 与
- []: 或
- (): 0或1
- a{}b: 重复a次到b次
- “”: 数据值 (不是变量, 其他可以是变量)
- a..b: r’[a-b]'
第三章
需求分析: 通过对应用问题以及环境的理解和分析, 刻画用户需求, 形成软件需求规格说明书 (SRS).
内容:
- 用户需求
- 功能需求
- 非功能需求: 速度, 可靠性等
- 领域需求: 软件所涉及的领域存在一些需求
步骤:
- 获取理解需求
- 描述分析需求: 对用户需求建模, 生成 SRS 和初步用户手册
- 评审: 对 SRS 复合评审
获取需求的方法:
- 访谈
- 结构化分析方法: 面向数据流自顶向下求精
- 简易应用规格说明书
- 建立快速软件原型
需求分析的方法
- 功能解析法: 功能, 子功能, 接口
- 结构化分析法: DFD + DD
- 信息建模法: ER 图
- 面向对象分析法
结构化分析法
- 结构化分析 SA
- 建立物理模型
- 抽象当前系统的逻辑模型
- 建立目标系统的逻辑模型
- 补充, 优化
- 结构化设计 SD
- 结构化程序设计 SP
DFD, DD, 加工规格描述 (PS), ER图, 状态转换图
状态转换图:
- 实心圆: 初始状态
- 圆外加一圈: 终止状态
- 圆角矩形: 状态, 可包括变量以及取值
- 箭头: 转移, 箭头上写事件
第四章
按照形式化的程度, 把软件工程使用的方法划分为非形式化, 半形式化, 形式化
- 非形式化: 自然语言
- 半形式化: ER图, 数据流图
- 形式化: 数学语言
非形式化的缺点: 矛盾, 二义性, 含糊性, 不完整性, 抽象层次混乱
分类
根据说明目标软件系统的方式:
- 面向模型: 构造数学模型, 描述系统行为
- 面向属性: 描述软件系统各种属性, 间接定义行为
根据表达能力:
- 基于建模
- 基于逻辑
- 基于代数
- 基于过程代数
- 基于网络
有穷状态机
六元组 $(J, K, T, S, F, P)$
- $J$: 状态集
- $S \in J$: 初始状态
- $F \subset S$: 终止状态集
- $K$: 输入集
- $P$: 谓词集合 (更大的系统状态)
- $T$: 转换集
转换: $S1 + K1 + P1 \Rightarrow S2$
Petri 网
- 圆圈: 位置
- 直线: 事件
- 箭头: 输入或者输出
- 圆圈里的点: 权标 (token)
可以把 token 定义为某种状态, 或者资源
token 沿着箭头流动, 指向事件的所有箭头都有 token 时, 该事件才能被激活. 激活会消耗指向事件的位置上的 token, 并增加输出箭头指向的位置上的 token. 增加或消耗的个数由箭头指定.
禁止线: 指向 token 的箭头变成圆圈, 表示没有 token 时, 才能够激活事件
z 语言
真你 🐴 复杂, 肯定不考
第五章
软件设计的阶段:
- 工程管理角度
- 概要设计阶段 (总体设计)
- 详细设计阶段
- 技术角度:
- 传统:
- 体系结构设计
- 数据设计
- 接口设计
- 过程设计
- 面向对象方法
- 体系结构设计
- 类设计
- 接口设计
- 构件级设计
- 传统:
总体设计的任务: 划分出系统的物理元素 — 程序, 文件, 数据库, 人工过程, 文档等
过程 (不是重点):
- 提供方案
- 选取合理方案
- 推荐最佳方案
- 功能分解
- 设计软件结构
- 设计数据库
- 制定测试文档
- 书写文档
- 审查复审
模块化
耦合
耦合: 模块之间互连程度
- 非直接耦合 (完全独立)
- 数据耦合
- 控制耦合
- 特征耦合
- 公共环境耦合
- 内容耦合
内聚
模块内元素彼此结合的紧密程度
- 功能内聚
- 顺序内聚
- 通信内聚
- 过程内聚
- 时间内聚
- 逻辑内聚
- 偶然内聚
衡量模块独立的标准
尽量使用数据耦合, 少用控制耦合和特征耦合, 限制公共环境耦合的范围, 完全不用内容耦合
尽量高内聚, 功能, 顺序这些
启发式规则
- 改进软接结构, 提高模块独立性
- 模块规模适中
- 深度, 宽度, 扇入, 扇出适中
- 深度:软件结构中控制的层数,它往往能粗略地标志一个系统的大小和复杂程度。
- 宽度:软件结构内同一个层次上的模块总数的最大值。
- 扇出:一个模块直接控制(调用)的模块数目。
- 扇入:有多少个上级模块直接调用它。
变换分析设计
- 确定变换中心, 逻辑输入和逻辑输出
- 设计第一层: 至少含有输入, 输出, 变换
- 细化之后的层
就是数据流图到程序结构图的转换:

第六章
过程设计的工具:
- 程序流程图
- 盒图
- PAD 图
- 判定表
- 判定树
- 过程设计语言
数据流: 盒图 (N-S 图), PAD 图
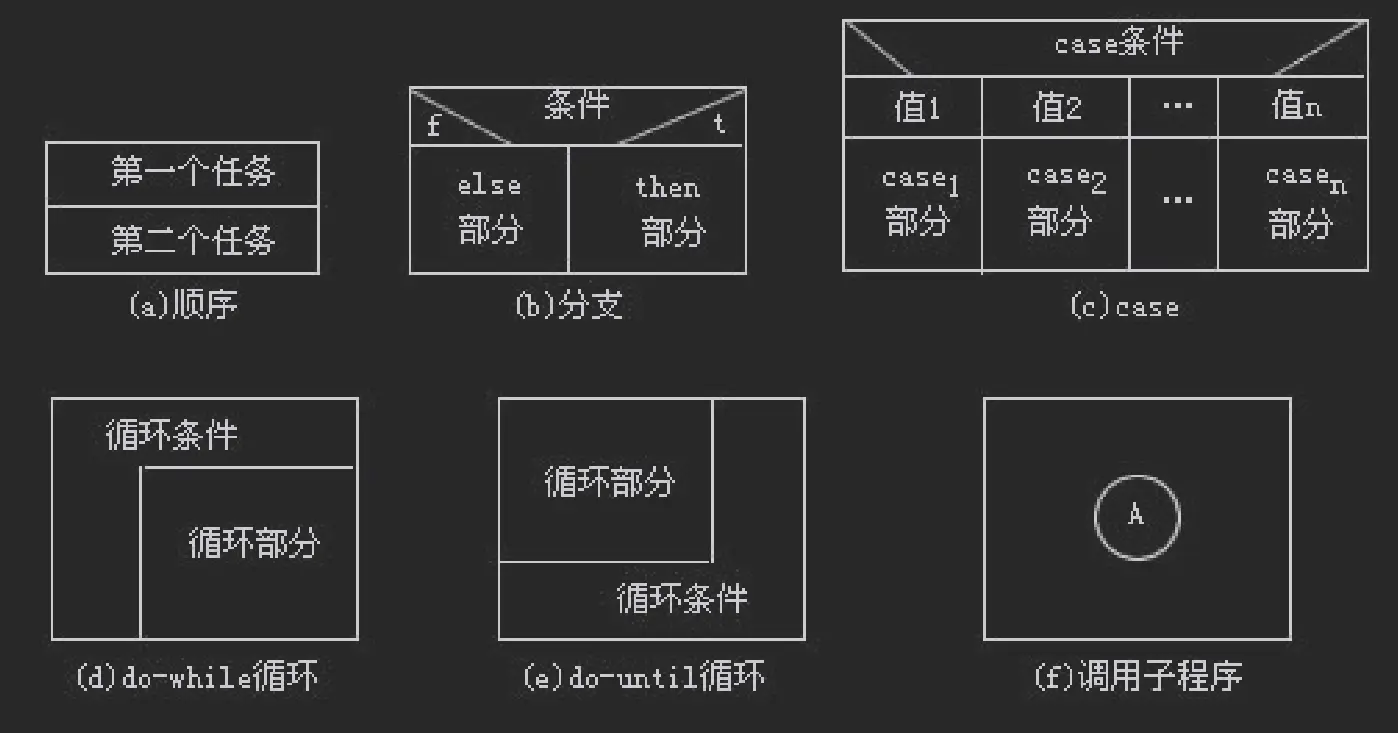
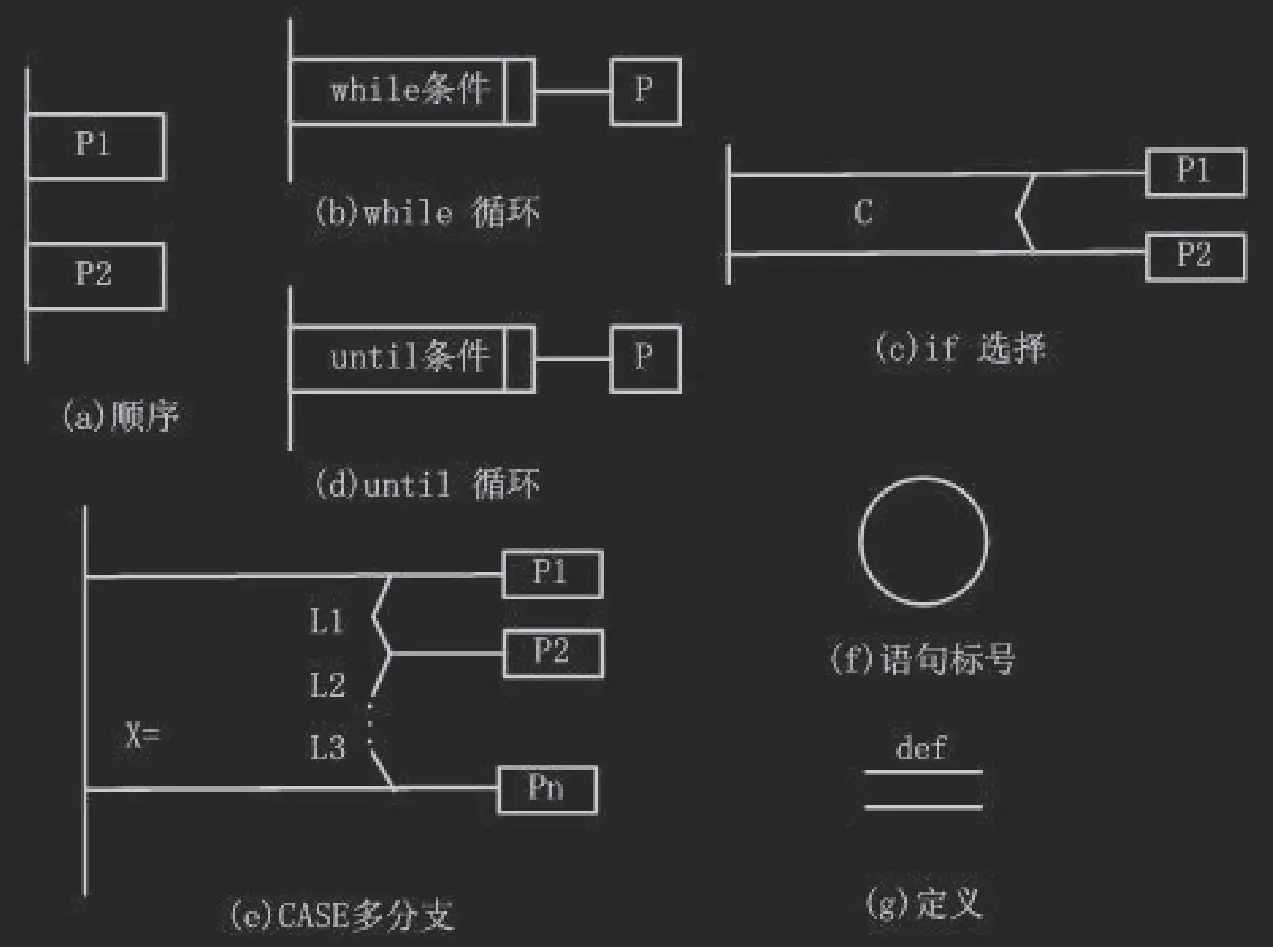
数据结构: Jackson 图
流图: 用有向图的方法大致描述程序流
环形复杂度: 图分割出的区域个数 (包括外区域)
第七章
注释
- 序言性注释: 每个模块的起始部分, 说明功能, 接口, 有关数据, 开发历史等
- 功能性注释: 描述代码功能, 提供附加说明
软件测试
目的: 尽可能多的发现并排除软件中的错误
白盒测试
逻辑覆盖:
- 语句覆盖: 每条语句
- 判定覆盖: 每个分支点都列出来, 然后找测试数据组, 覆盖所有的分支点
- 条件覆盖: 判定表达式的小条件列出来, 找测试数据组, 覆盖所有小条件 (如 A > 1 AND B = 0, 拆成 1) A > 1, 2) A <= 1, 3) B = 0, 4) B != 0)
- 判定/条件覆盖: 判定 + 条件
- 条件组合覆盖: 判定表达式整个条件组合, 找测试数据组覆盖 (A > 1 AND B = 0, 拆成 1) A > 1 AND B = 0, 2) A > 1 AND B != 0, 3) A <= 1 AND B = 0, 4) A <= 1 AND B != 0)
- 路径覆盖: 程序流的所有路径
黑盒测试
等价划分: 把程序的输入域划分成若干个数据类, 据此导出测试用例
根据每个输入的条件, 划分有效等价类和无效等价类.
Date 函数包含三个变量: 选取 year 和 month, 要求输入变量 year 和 month 均为整数值, 并且满足下列条件:
- 1970 ≤ year ≤ 2022
- 1 ≤ month ≤ 12
| 参数 | 有效等价类 | 无效等价类 |
|---|---|---|
| 年 | 1970≤year≤2012① | year<1970③, year>2022④ |
| 月 | 1≤month≤12 ② | month<1⑤, month>12⑥ |
然后找测试数据组, 分别覆盖有效等价类 1, 2, 以及无效等价类 3, 4, 5, 6
先根据有效等价类, 找数据尽可能多覆盖有效条件. 然后根据无效等价类, 找数据只覆盖一个无效条件, 列出表
边界值分析:
- 测试等价类的边界
- 不仅要考虑输入条件, 还要考虑输出情况 (输出等价类)
第八章
维护
维护: 软件已经交付使用后, 为改正错误或满足新的需求而修改软件的过程
- 改正性维护
- 适用性维护: 外部环境 (硬件等) 或数据环境 (数据库等) 变化, 适应变化
- 完善性维护
- 预测性维护
可维护性: 维护人员理解, 修改, 改进软件的难易程度
可维护性度量:
- 可理解性
- 可靠性
- 可测试性
- 可修改性
- 可移植性
- 效率
- 可使用性
副作用:
- 编码副作用: 引入 bug
- 数据副作用: 数据结构不匹配等 bug
- 文档副作用: 重写文档
利用历史文档, 简化维护工作
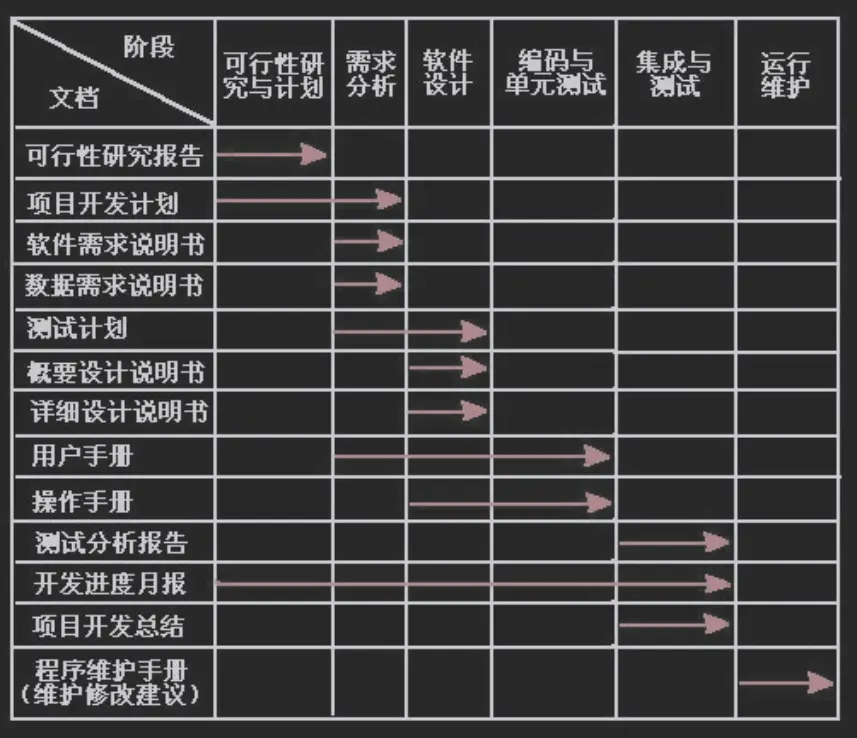
文档
表示对活动, 需求, 过程, 结果进行描述, 定义, 规定, 报告, 认证的书面或图示信息
作用:
- 提高软件开发过程中的能见度
- 提高开发效率
分类:
- 开发文档
- 管理文档
- 用户文档
第九章
面向对象
特征:
- 封装: 把客观事物抽象成类, 隐蔽信息, 只给允许的类访问
- 继承
- 多态: 内部实现不同, 外部接口相同
优点:
- 与人类习惯的思维方式一致
- 稳定性好
- 可重用性好
- 可维护性好
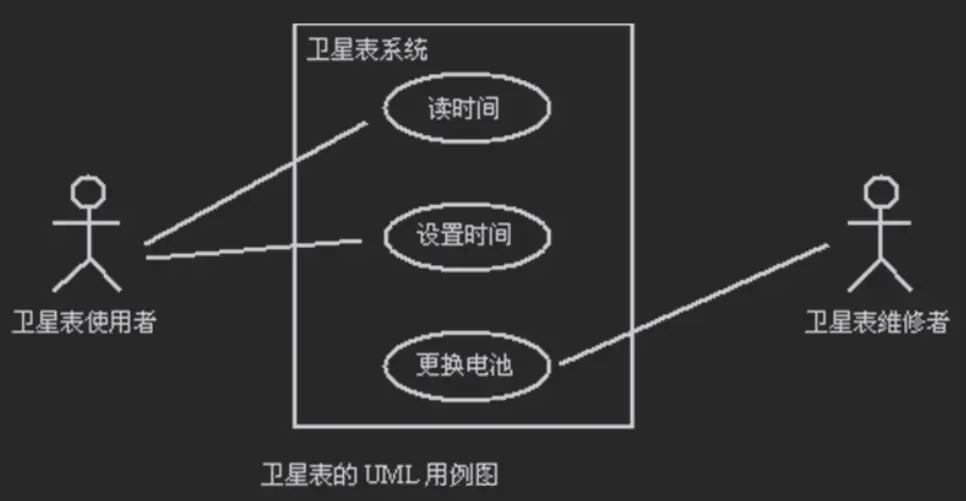
UML
用例图
不同的人使用系统的不同功能
类图
看你 🐴
一堆图不写了