
计算机网络 - 绪论
寄!
寄!

寄!

打了 miniL 后才知道了 shellcode 咋写, 这次国赛又碰上了, 就写一下 shellcode 吧.

大半年没训练, 加上早起做数电实验赶场导致状态不好, 被 pllj 的键盘薄鲨心态爆炸, 成绩惨淡…
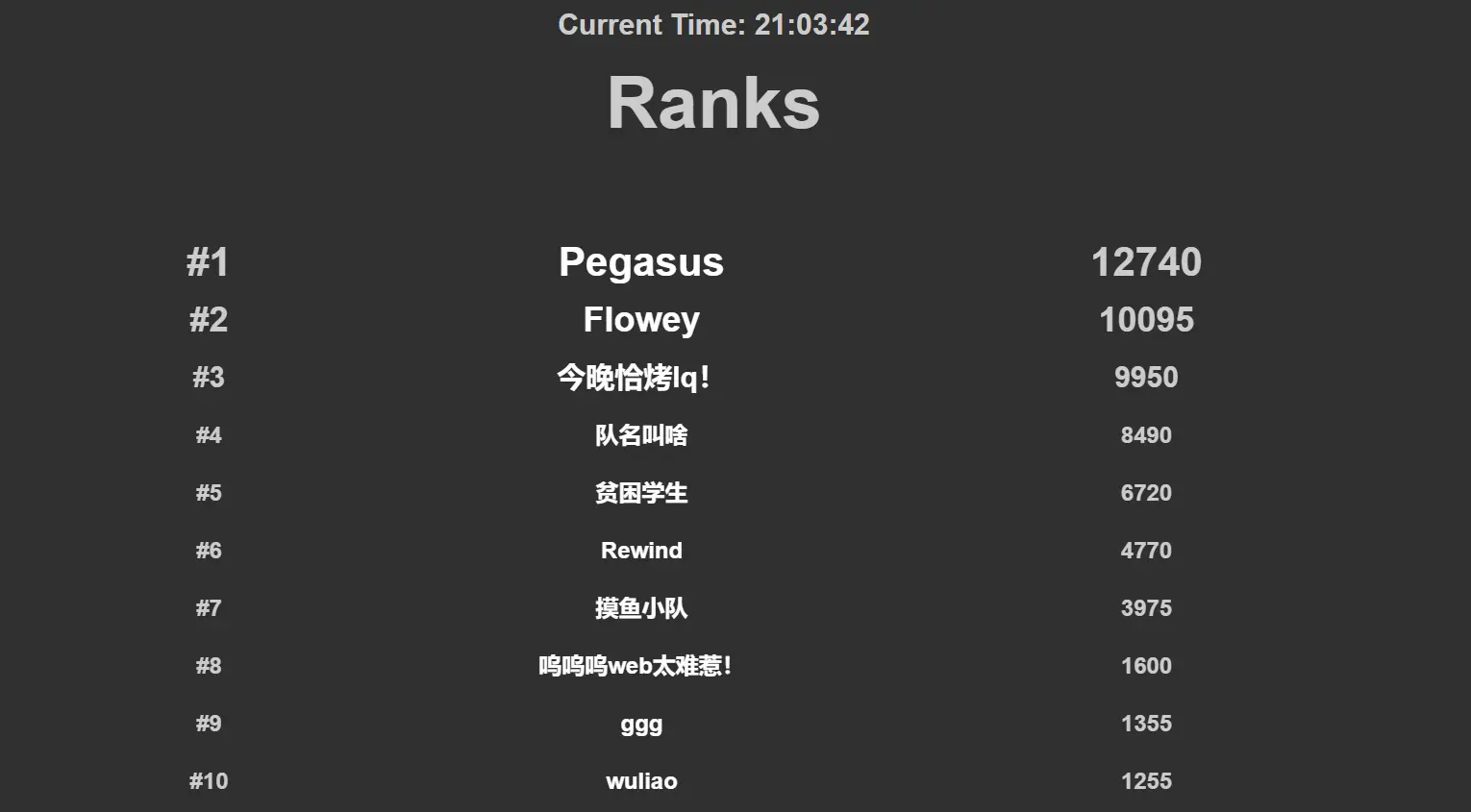
认真学了 pwn 后打的第一场比赛, 感觉良好. 之前听师傅们说 pwn 题出难了, 那赛前想着能出 1 题就是胜利, 结果出了 4 题, 超出预期一大截了. (后来发现人均 pwn 4 题 …)
缺人打到了校内第 6, 还不错.

准备学堆了, 不同版本的 glibc 对于堆的管理稍有不同 (比如高版本可能增加了一些补丁, 使得某些漏洞无法利用). 由于需要本地调试, 所以得先学一下怎么更换 glibc 版本.

通过栈溢出向 bp 之上的地方构造 ROP 链, 可以达到控制程序流的效果. 但是如果需要的 ROP 链比较长, 而溢出的大小又不足以构造 ROP 链, 那么这时就必须想其他办法了.
根据 ROP 的方法, 我们可以通过覆盖 old bp 去控制 bp 指向的位置. 如果可以再控制 sp 的位置, 比如有 pop sp 这种 gadget, 那么实际上就可以伪造一个栈, 或者说, 栈迁移.
一般来说, 迁移的位置需要有可读可写权限. 比如 .bss 节就是一个很好的目标位置. 或者在覆盖 buf 的时候, 可能会 “浪费” 很多空间, 也可以尝试把栈迁移到 buf 数组所在的栈上.
可能程序没有 pop sp, 但是程序一定有 leave. leave 可以达到栈迁移的效果. leave 可以分成两步, 即 mov sp bp; pop bp. 由于可以通过覆盖控制 bp, 那么把返回地址覆盖为 mov sp bp (leave; ret) 所在地址, 这样 sp 就可以控制了. 由于 leave 又会 pop bp, 所以只需要在 迁移到的 sp 上 布置一个 fake bp, 这样 pop bp 的时候就可以控制 bp 了. 总的来说, 就是可以通过覆盖返回地址为 leave; ret 达到同时控制 bp, sp, ip 的目的. 而这仅需要 8 或 16 个字节的溢出即可.