V8 Pwn Basics 1: JSObject
JS 有这几种基本数据类型: Undefined, Null, Boolean, String, Symbol, Number, Object. 数组和函数实际上是 Object. 显然, 最复杂的一种类型就是 对象. 本文主要介绍 Object 在 V8 中的表示.
Object 的本质是一组有序的 属性, 类似于有序字典, 即键值对有序集合. 键可以是非负整数, 也可以是字符串. 键为数字的属性称为 编号属性, 为字符串的称为 命名属性. 比如一个 object = {'x': 5, 1: 6};. 引用这个属性可以用 . 或者 [], 如 object.x, object[1].
每个属性都有一系列 属性特性, 它描述了属性的状态, 比如 object.x 的值, 它是否可写, 可枚举等等.
JSObject
每当创建一个对象时, V8 会在堆上分配一个 JSObject (C++ class), 来表示这个对象:
- Map: 指向 HiddenClass 的指针
- Properties: 指向包含 命名属性 的对象的指针
- Elements: 指向包含 编号属性 的对象的指针
- In-Object Properties: 指向对象初始化时定义的 命名属性 的指针
其中, Map 是用来确定一个 Object 的形状的, Proerties 和 Elements 都是 Object 中的属性. Properties 和 Elements 独立存储, 为两个 FixedArray (V8 定义的 C++ class), 编号属性一般也叫 元素, 他是可以用整数下标来访问的, 一般也就存储在连续的空间中. 而由于动态的原因, 命名属性难以使用固定的下标进行检索. V8 使用 Map Transition 的机制来动态表示命名属性.
Hidden Class
因为动态的特征, Object 的结构不是一成不变的, 比方说可以写这样的代码:
var a = {1: 1}
a['two'] = 2运行结束后, a = {1: 1, 'two': 2}
为了实现这一点, 对象的结构, 或者说 “形状”, 在 V8 中使用一个称为 Map 的类来表示, 它也称 Hidden Class, 或者 Shape.
Map (Hidden Class) 的结构如下所示:
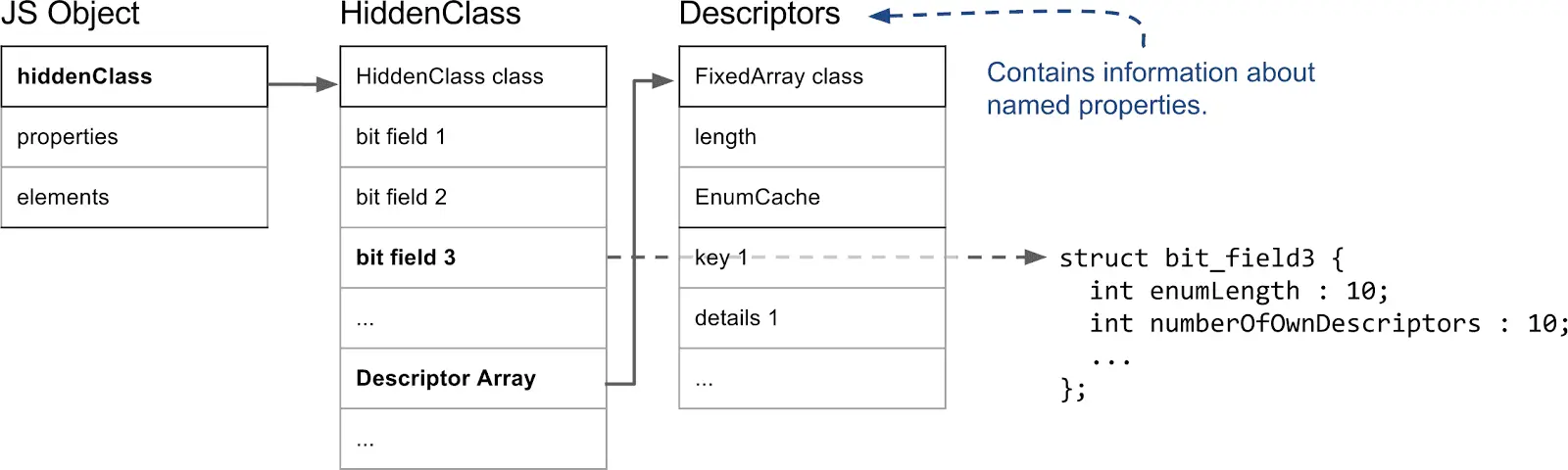
(很多字段如 Transition Array 这张图没画出来)
比较重要的字段如下:
- 第三个字段 bit field 3: (以某些位) 存储了属性的数量.
- Descriptor Array Pointer: 指向 描述数组 的指针, 描述数组包含命名属性的信息, 如名称, 存储位置偏移等. 这里的偏移指的是值在 properties 数组的哪一个位置
- Transition Array Pointer: 指向 Transition Array 的指针. 它相当于转换树上, 这个 Map 链接的边的集合
- back pointer: 指向转换树父亲节点 Map 的指针 (改字段与 construtor 复用, 因为根没有父亲).
V8 有两种方式来存储 命名属性, 对应了两种动态维护 Object 方式. 一种叫 快速属性, 一种叫 慢速属性 或 字典模式.
Fast Properties and Map Transition
快速属性分两种, 一种是每个 Object 的 in-object properties, 直接访问, 非常快速, 但是没有动态支持. 另一种是存在 Map 的 Descriptor Array 中, 使用 Map Transition 来支持动态, 也就是 JS 的 “基于原型继承”.
每次新增命名属性时, 都会基于原来的 Hidden Class 做 转换, 即新建一个 Hidden Class, 并维护信息, 同时维护两条有向边 (Transition Array 里向前一条, back pointer 向后一条), 组成一个树形结构.
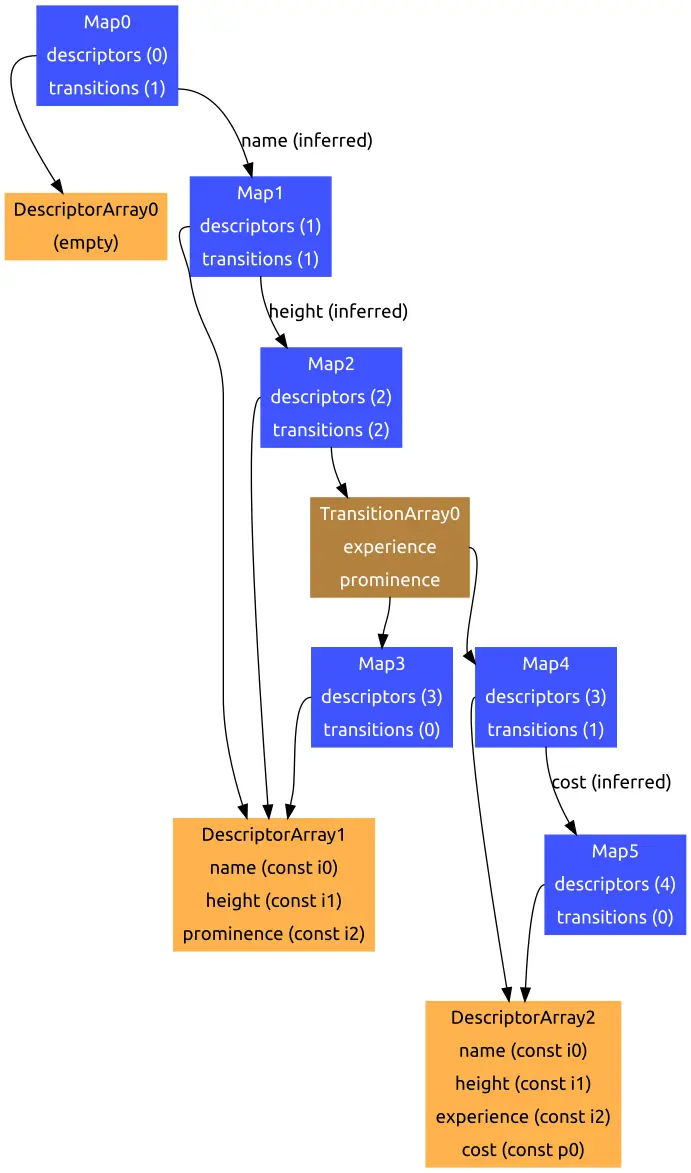
在添加命名属性的时候, 除了 Map 会做变换, 其中的 Discriptor Array 也会更新, 但不是每个 Map 都有独立的 Discriptor Array, 因为他们一定程度上可以复用来节省空间. 如下面的代码:
function Peak(name, height, extra) {
this.name = name;
this.height = height;
if (isNaN(extra)) {
this.experience = extra;
} else {
this.prominence = extra;
}
}
m1 = new Peak("Matterhorn", 4478, 1040);
m2 = new Peak("Wendelstein", 1838, "good");
m2.cost = "one arm, one leg";在动态添加的过程中, 如果我们看进入 if 的那个分支, Peak 的结构 (属性名以及位置) 变化应该是这样的:
Map0: {}
Map1: {name}
Map2: {name, height}
Map3: {name, height, experience}可以发现每个 Map 重复的部分其实很多. 除了 Map0 (因为 {}?) 外, 其他的 Map 共用一个 Descriptor Array, 为 {name, height, experience}, 而 Map1 的属性数量为 1, 它不使用后面两个属性; 同理 Map2 的属性数量为 2, 不使用最后一个. 这样就完成了复用.
不能复用的 Descriptor Array 则会新建一个, 如上述代码又进入 else 分支, 并动态添加 cost 属性, 会产生 {name, height, prominence, cost}
上述代码的整个转换树 (省略 back pointer) 如下图所示:
Slow Properties and Dictionary Mode
当一个 Object 删除命名属性删的多了, 树形结构自然不好维护, 这时 V8 会转而使用类似字典的方法, 存储在 JSObject 的 Properties 中, 然后通过哈希来访问. 使用了字典模式后, Descriptor Array 指针就空了, 也不使用 Map Transition.
字典模式的 Map 结构如下图:
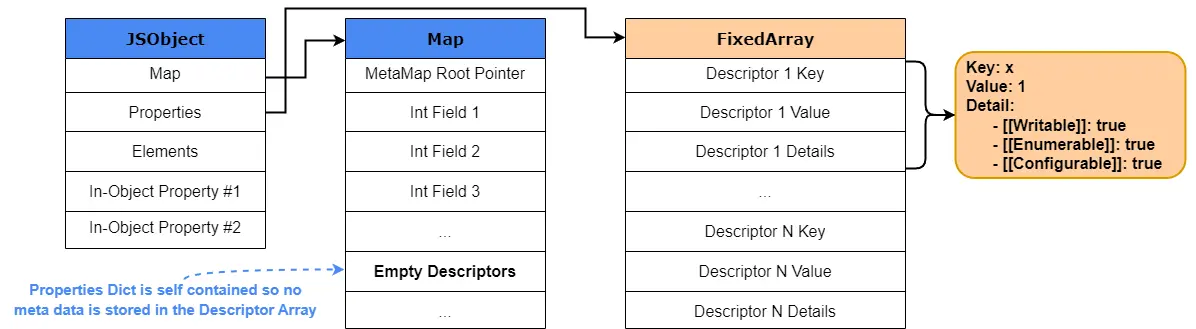
这里的 value 直接就是值, 而不是偏移了.
编号属性 (Elements)
JS 的数组也是一种 Object. 我们在使用数组的时候, 一般来说会连续访问. 所以编号属性 (又称元素) 直接存放在连续的内存中, 通过 Map 的 Elements 指针字段索引过去. 增加元素的时候不会有 Map Transition 的操作.
V8 对元素的类型进行了细分, 我们需要理解的是 SMI_ELEMENTS, DOUBLE_ELEMENTS 和 ELEMENTS. SMI 是小整数, DOUBLE 是浮点数, ELEMENTS 就是其他. 数组会维护一个元素类型. 比如 x = [1, 2, 3] 的类型为 SMI, 而 x = [4.4, 5.5] 的类型为 DOUBLE, x = ['789'] 的类型为 ELEMENTS. 这三种类型是包含关系, JS 数组中可以同时出现整数, 小数, 字符串等, 而元素类型是数组的属性而不是元素的属性, 所以细化分类之后一定要有兼容性. 比如 x = [1, 2.0] 的类型为 DOUBLE, 如果向 x 中再添加一个 '3' (字符串), 那么数组 x 的类型将转换为 ELEMENTS. 而这种转换是单向的, 即使删除了所有字符串, 已经是 ELEMENTS 的不会转回 DOUBLE.
除了元素类型的区别, V8 还区分 packed 和 holey. packed 表示数组里所有空间都使用, 而 holey 表示有没有使用的空间 (空洞). 如 x = [1, 2, 3] 是 PACKED_SMI, 而 y = [4.4, , 5.5] 是 HOLEY_DOUBLE, 因为 y[1] 没有定义. 这种区分主要是 V8 用于优化空间的. 同样 PACKED 到 HOLEY 也是一个单向的转换.
数组也有快速模式和慢速模式, 一般来说会使用快速模式, 即数组空间连续. 如果一个数组非常稀疏, 那么 V8 将会使用慢速模式, 创建一个字典来索引元素项目.
属性记录
属性的键值和属性特性在 Descriptor Array, Preperties 中均使用 (key, value, detail) 三项来记录, key 是键名, value 是值, detail 是属性特征, 包括 writeable, enumerable, configurble. 元素的慢速模式也采用这种方式存储. 快速模式就是一个连续空间, 类似于数组.
elements 和 properties 属于 JSObject 的"成员", 实际上它们也用一个 Map 来表示元素的类型, 不过最后实际的类型依然 取决于 JSObject 的 Map 类型.
数据在内存中的表示
V8 在内存中主要存储三种数据, 指针, SMI 和浮点数. 一个对象的元素可能既有数字又有其他对象, 比如 var a = []; a[0] = 1; a[1] = {}. 所以需要一种不会导致类型混淆的存储方法. 而又由于 SMI 实在是很常用, 将它封装成一个对象再存储指针的话, 性能会下降.
指针标记 (Pointer Tagging)
V8 的地址分配是对齐字长的, 所以指针的后两位是 0, 可以在这里做标记. 最低位为 1 表示这是一个指针而不是 SMI, 倒数第二低位标记强弱引用; 如果最低位为 0, 则表示这是一个 SMI. 所以在 32 架构位下, 一个 SMI 是 31 位的, 存储在高 31 位中, 最低位是 0, 表现在内存中就好像给实际值乘以了一个 2.
|----- 32 bits -----|
Pointer: |_____address_____w1|
Smi: |___int31_value____0|
而浮点数是 64 位的, 在 32 位架构下需要封装成一个 “对象”, 存的时候用的是地址.
而在 64 位架构下, 早期版本的 V8 (应该是 2020 之前), 指针和 SMI 在内存中会长这样:
|----- 32 bits -----|----- 32 bits -----|
Pointer: |________________address______________w1|
Smi: |____int32_value____|0000000000000000000|
浮点数可以不必全封装起来, 对于只由浮点数组成的数组如 FixedDoubleArray, 可以只存储浮点数. 一旦对象形状发生了变化, 需要存一个地址, 这时才将浮点数封装.
指针压缩
显然无论是地址还是 SMI, 都有空余的空间没有使用.
较新版本的 V8 把堆空间安排在一个连续的 4 GB 区域中, 然后把堆的基址存在根寄存器 (r13) 中. 这样用一个 32 位的偏移就可以找到实际的地址. 所以指针只需要存储 32 位的偏移即可.
|----- 32 bits -----|----- 32 bits -----|
Compressed pointer: |______offset_____w1|
Compressed Smi: |____int31_value___0|
这样指针和 SMI 都存在 32 位的空间中, 减少了内存的使用. 同时这里 SMI 也回到了 32 位架构下的表示方式, 高 31 位有效, 最低位为 0.