卷积神经网络基础
还是学习 Victor Zhou 大佬. 博客 CNNs, Part 1: An Introduction to Convolutional Neural Networks
卷积神经网络(CNNs)是cv里的东西,,,
考虑一张图, 它不仅很大, 而且有RBG三个数据, 所以如果用最基本的神经网络的话, 一张图的输入层有 $3nm$ 个神经元, 这样隐藏层也很多, 导致训练困难.
从视觉角度来说, 单独的像素点意义不如它和它周围的某些点的整体明显. CNNs大概就是考虑相邻像素点.
过滤器
过滤器是一个二维方阵, 用类似滑动窗口的思想去对应输入图片的某些部分. 把它们压成一个向量, 然后做点积, 结果放在对应部分, 这样就得到了处理后的图像.
就类似这样, 看看就能懂:

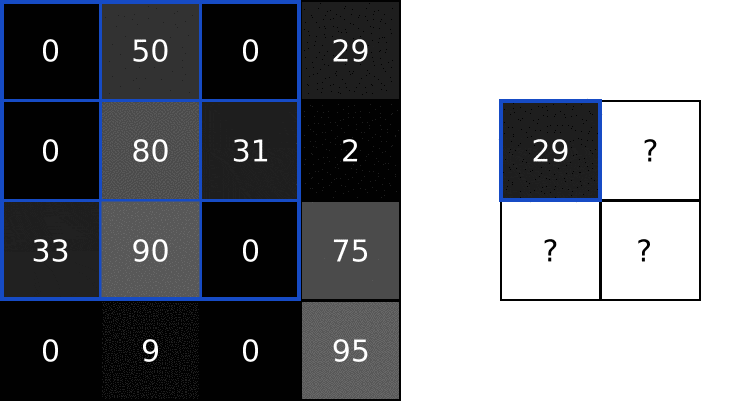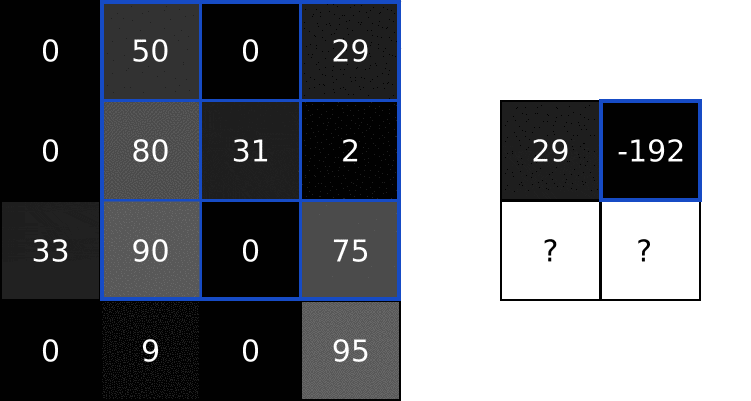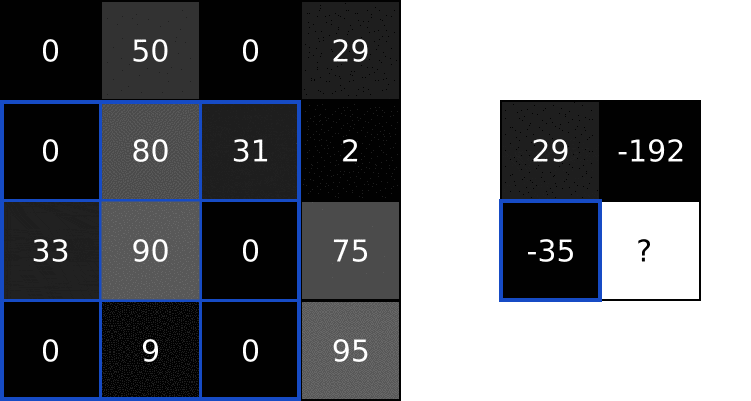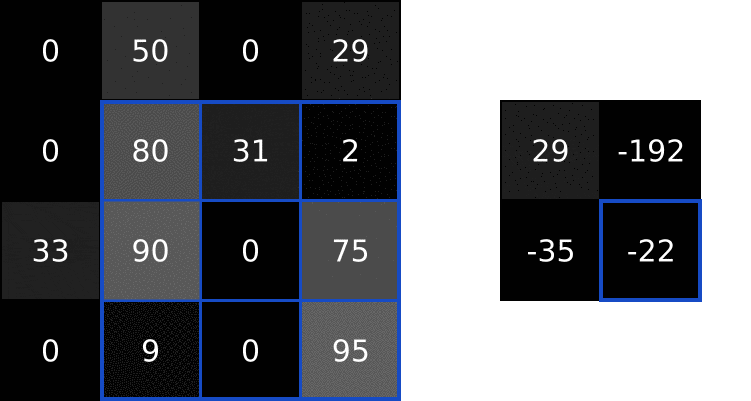
过滤效果
过滤器不同取值能够提取图片的不同特征, 原博客用计算机学家都喜欢的一个妹子的图片做了举例, 这里就不搬了(懒)
填充
就这样:

处理后的图和原图大小一样.
如果不填充, 那么处理后的图片大小就是 $(n-2) \times (m-2)$.
卷积层
过滤器可以设置多个, 能够提取不同的特征. 这些过滤器就在卷积层上.
池化层
$-2$还是太大了. 把图片稍微缩小一点, 人眼看起来该有的特征还是有的. 那么神经网络看起来该有的特征也应该有. 池化就是干了这么个操作.

上图取值用了max, 实际上可以用max, min, avg, 或者其他函数.
Softmax 激活函数
输出层的激活函数用Softmax. 他输出的是这个张图片中可能是某些物品的可能性.
比如识别 $0 \sim 9$ 的手写数字, 那么就有10个输出, 其中第$i$个输出代表该图片是数字$i$的可能性.
显然最后我们应该选可能性最大的那个当作我们识别出的数字.
网络结构
大概长这样:

交叉熵损失
在CNNs中用**交叉熵损失(Cross-Entropy Loss)**来评价模型, 而不是均方误差.
Softmax输出的是可能性, 我们只考虑可能性最大的那个输出. 如果输出很接近1, 那么这样的模型是较为准确的. 所以, 可以用交叉熵来确定损失函数:
$$L(p_c) = -\ln(p_c)$$
其中, $p_c$ 是该图像属于分类$c$的可能性.
当然我们还是让$L$越小越好. $L = 0$就表示了$p_c = 1$. 训练还是一样, 最小化$L$.
就没了, 也不是很难.